Level: Beginners
Original Post: November, 2016
It was only a few months after Power BI was born, that Matt first posted on this topic. At that time, his focus was still primarily on Power Pivot in Excel, as Power BI was still in its infancy. Despite this, understanding when it is appropriate to create Lookup (Dimension) tables remains an important foundation concept for Power BI Semantic Models today. As a result, I am updating this article to assist Power BI new-commers to understand when it is important to create a lookup table and when it is fine to use native columns in a Data (Fact) table. Although this post is rated as a beginner topic, there is so much to learn, and you can only absorb so much content before your head begins to explode, that you may find yourself learning this topic for the first time now even though you would consider yourself an intermediate user. In other words, I hope to make this story sufficiently compelling that it is good for everyone, either as a review, a confirmation of what you know, or as a new learning opportunity.
It is also worth pointing out that this topic does not mean the difference between “it works” and “it doesn’t work”. You can be successful using Power BI (and Power Pivot) without understanding this concept well. But it can make a big difference to usability of your model and certainly performance (in some cases). And not least of all, if you want to get better and advance your Power BI skills, you simply must understand these principles well.
So with that, let’s dig in!
Topics Covered in This Post
In this post I cover the following scenarios to help explain some of the nuances and benefits of using lookup tables (or not):
- Simple data models
- Inbuilt time intelligence functions
- To Simplify Your DAX formulas
- Pointless dimension tables
- Multiple data tables
- Simple business communication
Tale of Two Tables
Before we move on, it is worth restating the definition of the 2 different types of tables that make up a standard Star Schema, so it is clear in your mind.
There are 2 different types of tables in a Power BI semantic model. There are dimension tables (I call them lookup tables) and there are fact tables (I call them data tables or event tables). These two table types are very different and understanding the difference is fundamental to understanding and using Power BI properly.
Lookup Tables (Dimensions)
Lookup tables contain the data that helps you describe elements of the events that have occurred. The information within a lookup table is typically about 1 business concept/object, i.e. Customers, Products, Time, etc.
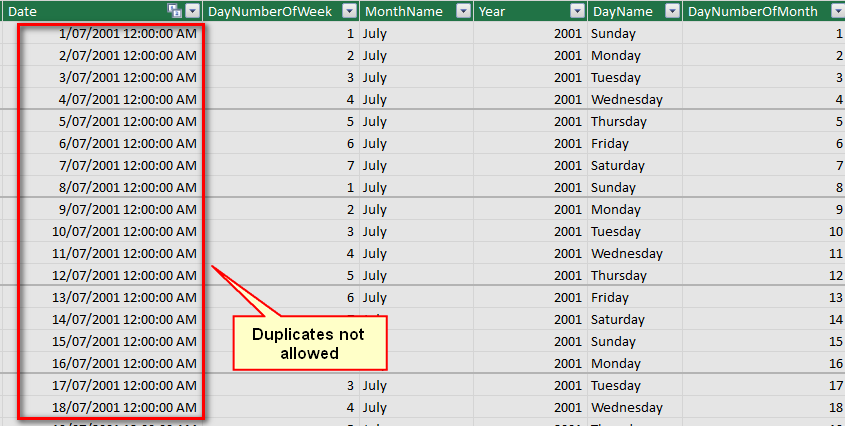
Lookup tables always have the following features:
- There is always a column of data that uniquely identifies each row of data in the table. In database terms this is called the primary key. In the customer table it would be the customer number, in the products table it is the product code, in the calendar table it is the date, and so on for any lookup table.
- There can be NO DUPLICATES in this key column – every row must be unique
- There can be 1 or more additional columns in each lookup table that provide more information about that primary key column.
i.e. in the calendar lookup table, the date is the primary key. Other columns such as Day Name, Month Name, Year, Day of Week number, etc all provide detail about the date key. These additional columns describe the dates, allowing us to understand concepts like which dates are a Friday, and that Friday is the 5th day of the week. You can consider these descriptive columns as providing metadata about the primary key.
Data Tables (Facts)
Data tables are typically transactional in nature and contain information about a record of events that have occurred (i.e. event table). It could be sales data, budget data, General Ledger data from a financial system, call centre call data, or any other data about activities of some type.

Data tables have the following features:
- There is no requirement that a data table must have a primary key.
- There needs to be 1 column that can be connected to relevant lookup tables (assuming you want to connect these tables). In database terms, this column is called the foreign key. It should be obvious that if you want to join your data table to your product table, you must have a column that defines the product in your data table.
- Duplicates are allowed in data table columns.
i.e. many sales occur on each day, many sales occur for each product.

Joining the Tables
You should not join data tables to other data tables. Data tables should always be joined to lookup tables using the Lookup Table primary key column as the join column.
I am using the Adventure Works database in the image below. I have placed the lookup tables in my data model at the top of the window and the data table below. This is the Collie Layout methodology; it gives the user a visual clue that the tables above the relationships (you have to “look up” to see) are the Lookup Tables, and the table(s) below the relationships are the transactional data tables. This layout is not required for Power BI to function correctly; it is simply a recommended layout that simplifies the communication of table type to the user and is an easy way to remember. Technically, this data structure is called a star schema.
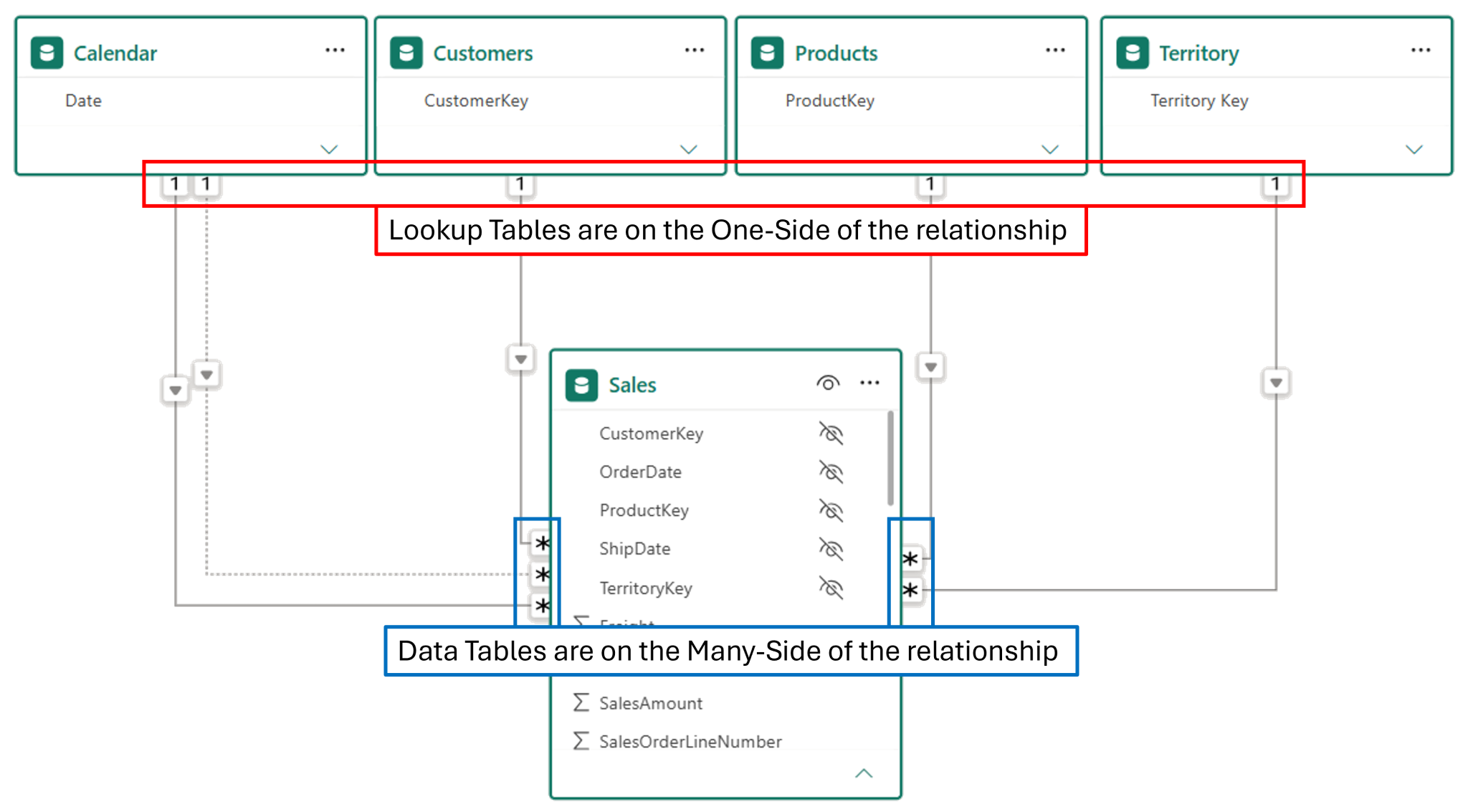
When To Use Lookup Tables
Back to the point of this post. When should you use lookup tables and when is it OK to leave a descriptive column in your data table?
You do not “need” to use lookup tables at all to make your data model work in Power BI – it is okay to simply load a data table and go from there for very simple reports. Having said that, read on to find out the nuances of some common scenarios.
Simple data models
Let me start by covering when it is OK to not use any lookup tables. If your data meets the following scenario it is fine to ignore lookup tables:
- Your data set is small. What defines small depends of course. Certainly 10,000 – 250,000 rows of data is considered small (tiny actually in the context of Power BI). It is less important to efficiently store your data when your data set is small and hence a single flat data table can be OK.
- Your data doesn’t contain too many columns (this is a topic in its own right and outside of the scope of this post). If you have lots of columns (eg >15) then even 250k rows of data can become problematic and non-performant. But if you have a few columns, then maybe you don’t need lookup tables.
- Your data table already contains all the columns you need for your analysis.
- You don’t need to use any inbuilt time intelligence calculations (more on that below).
- You only need to write simple DAX formulas (such as SUM formulas).
If this is your scenario, then you don’t need lookup tables at all. However if you always operate in this simple scenario then you will not advance your DAX knowledge to the next level, so keep that in mind. This scenario with no lookup tables is quite rare and is probably limited to Excel users that already have their data in a single flat table. It is also worth pointing out that once you get to more advanced scenarios with DAX formulas, then you can get yourself into serious problems unless you create a star schema. This is a complex topic and you (and I) don’t need to understand the technical reasons why – we just need to know what to do so it works. Once you start writing more complex formulas using CALCULATE(), you would be well advised to set up a start schema. I would never write a CALCULATE() measure over a flat table.
Inbuilt Time Intelligence Functions
If you intend to take advantage of one of the many inbuilt time intelligence functions in DAX, it is mandatory you have a calendar lookup table. You will know if you are using an inbuilt time intelligence function, because it will ask you to provide Dates as an input (e.g. SAMEPERIODLASTYEAR(Dates) ). Examples include calculating sales last year, sales year to date, etc. We cover calendar lookup tables in depth in this article. It is possible to do custom time intelligence calculations (not inbuilt) using a single data table, but I don’t recommend it. If time is an important part of your data, then I strongly recommend you get a calendar lookup table and go from there.
Examples of Inbuilt Time Intelligence calculations:
Total Sales PY = CALCULATE ( [Total Sales], SAMEPERIODLASTYEAR( ‘Calendar'[Date] ) )
Total Sales YTD = TOTALYTD ( [Total Sales], ‘Calendar'[Date] )
To Simplify Your DAX Formulas
While it is possible to use a simple data model with a single data table and no lookup tables (as mentioned above), once you have more complex analysis needs (anything other than what can be achieved with dragging a column onto values) you will need to write some DAX formulas to create the business insights. In my experience it can be easier to write DAX formulas when you have lookup tables, particularly when you need to modify the natural filtering behaviour of your data model (change the filter context). “How” to do this is also out of scope for this topic, but be aware that this is another reason to move on from a single data table.
Pointless Dimension Tables
There is no point creating a dimension/lookup table without a reason and certainly not if there are only 2 columns in the lookup table. This will make more sense with an example.
Take the Adventure Works data model as shown below. It contains a lookup table (Products) with 2 columns, one for Product Key and one for Product Name. The lookup table is joined to the data table using the primary key (of course).
The data in this lookup table would look something like the table shown below – only 2 columns (but a lot more rows of data than shown in this image of course).
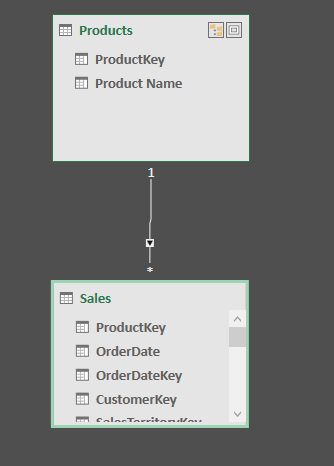
People that have some understanding of traditional relational databases will be aware that relational databases will store the data in the first column (ProductKey) a lot more efficiently than the data in the second column (Product Name). It is therefore common to think that it is more efficient to store the product key in the data table and put the product name in the lookup table only, but this is not the case in Power BI. Power BI uses the VetiPaq storage engine to compress and store the data. As you might guess by the name, the VertiPaq engine stores the data vertically, in columns, and has a number of compression techniques to ensure it does so extremely efficiently. Exactly how it does this is outside of the scope of this article, but what you should take away from this is that Power BI does not store the same way a traditional SQL database stores data but instead uses a specialized storage engine that means there is no (or little) space saving benefit in storing the product code in the data table instead of storing the product name. In addition, every relationship in your semantic model comes at a cost/overhead. This is why this lookup table is called a junk dimension. If the only reason you have this lookup table is to join the single column “Product Name” to the data table via the product key, then it would be just as good to load the product name directly into the data table and drop the product key all together.
If your data already has the product name (and not the product key) in the data table, and you are thinking of creating this lookup table, then you may want to think again. That being said, there are other reasons why you may want to keep the primary key and lookup table including, but not limited to:
- if you have more than 2 columns in your lookup table (i.e. Product Key, Product Name, Product Category).
- if your product names are not unique (often the product key is managed more rigorously than the name)
- if your data table already has the product key in the table and it is easier to do it this way.
If your data table contains a column that is not related to any other column as a logical object and you are wondering if you should build a lookup table for it – the answer is no – don’t do it. Just use the column in your data table.
Multiple data tables
As you probably know already, it is possible to have multiple data tables in your data model. In fact this is one of the many great things about Power BI.

However, as I mentioned at the start of this post, generally speaking it is not advisable to join one data table to another data table in Power BI. There are of course exceptions to this, but again outside the scope of this article. If you want to use multiple data tables in your data model, you must join them through common lookup tables. It therefore follows that if you have multiple data tables in your data table, you should load lookup tables even if those lookup tables would otherwise be considered junk dimensions.

Simple Business Communication
There is a clear benefit to business users if you logically group your columns of data into lookup tables that make business sense. It can be hard for users if they need to hunt through the data table for information about a customer, or a product, etc. It is a much better end user experience if there are logical groupings of columns of relevant data in a table called Customer, Product, etc. Given the end users may be creating their own reports using the field list in the Data pane to find the relevant data, grouping the data into lookup tables can really improve the end user experience.
Flatten Your Lookup Tables
To the above point, you should also consider flattening out your data into a single lookup table if you can. The following snowflake model is feasible and will work in Power BI, but it is hardly user friendly. In the image below there is a Product Details lookup table, and then a Product Subcategory lookup table of the Product Details table, and a Product Category lookup table of the Product Subcategory table.
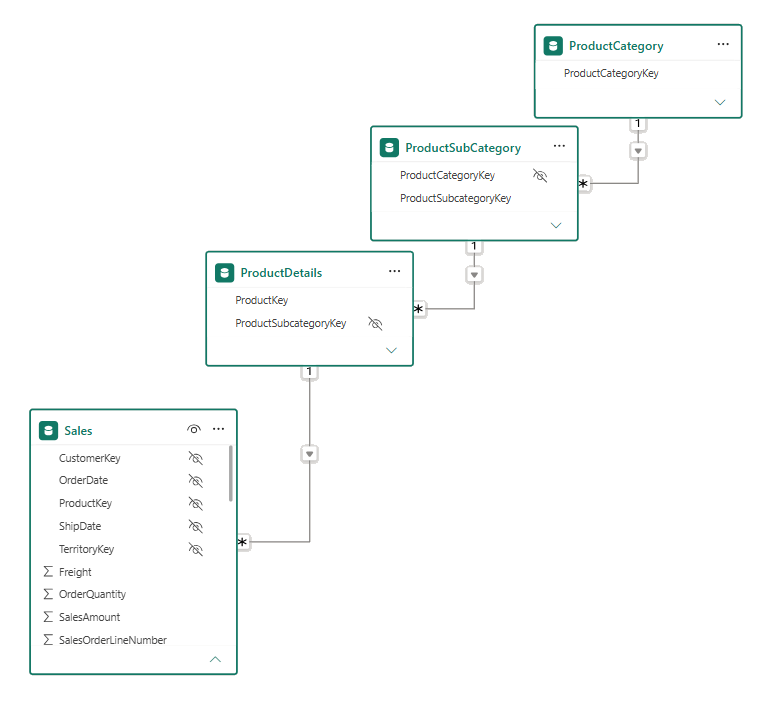
But if you deploy this model, it is likely to be confusing to the end user. Remember they will be building reports using the field list, and they will need to go searching across different tables to find the columns of data they need to use. It is much better to flatten the data from the additional lookup tables into a single Product lookup table if you can. Also flattening these tables will remove the extra relationships and this will make the model more efficient (every relationship comes at a cost). And importantly, your DAX will be easier to read, write and troubleshoot if there is only a single relationship between the descriptive column and the column to be aggregated.
Wrap Up
Hopefully this article has helped clarify when and where to use lookup tables. Let me know your thoughts and/or any questions that remain unresolved in the comments below.
Hey there, You’ve performed an incredible job. I’ll definitely digg it and in my opinion recommend to my friends. I’m confident they will be benefited from this site.
I’m still learning from you, while I’m trying to reach my goals. I definitely love reading everything that is posted on your website.Keep the posts coming. I enjoyed it!
Hello there, just became aware of your blog through Google, and found that it’s truly informative. I am gonna watch out for brussels. I’ll be grateful if you continue this in future. Numerous people will be benefited from your writing. Cheers!
Thanks – Enjoyed this post, how can I make is so that I get an update sent in an email whenever there is a fresh update?
That is very fascinating, You are a very skilled blogger. I have joined your rss feed and look forward to in the hunt for extra of your wonderful post. Also, I have shared your web site in my social networks!
Very nice post and straight to the point. I don’t know if this is truly the best place to ask but do you folks have any thoughts on where to get some professional writers? Thx 🙂
Magnificent goods from you, man. I’ve understand your stuff previous to and you’re just too great. I actually like what you’ve acquired here, certainly like what you are stating and the way in which you say it. You make it entertaining and you still care for to keep it wise. I cant wait to read far more from you. This is really a wonderful site.
As I web-site possessor I believe the content matter here is rattling wonderful , appreciate it for your hard work. You should keep it up forever! Good Luck.
This design is incredible! You most certainly know how to keep a reader amused. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Fantastic job. I really loved what you had to say, and more than that, how you presented it. Too cool!
Some genuinely excellent articles on this internet site, thanks for contribution.
obviously like your web-site but you need to test the spelling on several of your posts. Many of them are rife with spelling issues and I find it very bothersome to tell the reality however I¦ll surely come back again.
I conceive you have mentioned some very interesting points, appreciate it for the post.
I’m curious to find out what blog platform you happen to be working with? I’m experiencing some minor security issues with my latest website and I’d like to find something more secure. Do you have any recommendations?
You could definitely see your skills within the work you write. The arena hopes for even more passionate writers such as you who aren’t afraid to say how they believe. All the time follow your heart.
I have been absent for a while, but now I remember why I used to love this blog. Thank you, I will try and check back more often. How frequently you update your site?
Hello. Great job. I did not anticipate this. This is a splendid story. Thanks!
Thank you for sharing superb informations. Your web-site is very cool. I’m impressed by the details that you’ve on this website. It reveals how nicely you understand this subject. Bookmarked this web page, will come back for extra articles. You, my friend, ROCK! I found simply the information I already searched all over the place and simply could not come across. What a perfect web-site.
Great blog here! Also your website loads up very fast! What web host are you using? Can I get your affiliate link to your host? I wish my website loaded up as fast as yours lol
Hi! Do you use Twitter? I’d like to follow you if that would be ok. I’m undoubtedly enjoying your blog and look forward to new updates.
We stumbled over here coming from a different web address and thought I might check things out. I like what I see so now i am following you. Look forward to looking into your web page yet again.
I just could not leave your site before suggesting that I actually loved the standard information an individual supply on your guests? Is going to be again steadily in order to investigate cross-check new posts.
Just what I was looking for, thanks for putting up.
I have read a few good stuff here. Certainly price bookmarking for revisiting. I wonder how so much effort you put to create the sort of fantastic informative web site.
This design is incredible! You most certainly know how to keep a reader entertained. Between your wit and your videos, I was almost moved to start my own blog (well, almost…HaHa!) Fantastic job. I really enjoyed what you had to say, and more than that, how you presented it. Too cool!
Thank you for sharing excellent informations. Your web site is very cool. I’m impressed by the details that you have on this website. It reveals how nicely you understand this subject. Bookmarked this website page, will come back for extra articles. You, my friend, ROCK! I found simply the information I already searched everywhere and just could not come across. What a perfect web site.
I’m not that much of a internet reader to be honest but your blogs really nice, keep it up! I’ll go ahead and bookmark your site to come back later. Cheers
I consider something really special in this website .
Whats up very cool site!! Man .. Beautiful .. Amazing .. I will bookmark your web site and take the feeds also?KI am satisfied to search out numerous useful information right here in the submit, we’d like work out more techniques on this regard, thanks for sharing. . . . . .
great publish, very informative. I’m wondering why the opposite experts of this sector don’t realize this. You should proceed your writing. I am confident, you’ve a huge readers’ base already!
you could have an incredible weblog here! would you prefer to make some invite posts on my weblog?
I am often to blogging and i really appreciate your content. The article has really peaks my interest. I am going to bookmark your site and keep checking for new information.
I’ve recently started a site, the information you provide on this web site has helped me greatly. Thanks for all of your time & work. “Marriage love, honor, and negotiate.” by Joe Moore.
fabuloso este conteúdo. Gostei muito. Aproveitem e vejam este conteúdo. informações, novidades e muito mais. Não deixem de acessar para descobrir mais. Obrigado a todos e até a próxima. 🙂
—
This content is fabulous. I really enjoyed it. Take advantage and check out this content. Information, news and much more. Don’t forget to access it to discover more. Thank you all and until next time. 🙂
This really answered my downside, thank you!
I want to show my thanks to the writer just for rescuing me from such a instance. Just after browsing throughout the world wide web and coming across basics that were not helpful, I figured my entire life was over. Living without the approaches to the difficulties you’ve fixed by way of your main website is a critical case, as well as ones which could have negatively damaged my entire career if I hadn’t come across your website. Your good skills and kindness in touching all the things was invaluable. I am not sure what I would have done if I hadn’t come upon such a point like this. I’m able to at this point relish my future. Thanks for your time very much for the impressive and effective help. I won’t hesitate to suggest your blog post to anybody who requires support on this subject.
Can I just say what a relief to search out someone who really is aware of what theyre talking about on the internet. You definitely know easy methods to bring a difficulty to gentle and make it important. More people have to read this and understand this side of the story. I cant consider youre no more fashionable because you definitely have the gift.
This is very interesting, You are a very skilled blogger. I’ve joined your feed and look forward to seeking more of your magnificent post. Also, I have shared your site in my social networks!
Some truly excellent information, Glad I observed this. “Never put off until tomorrow what you can do the day after tomorrow.” by Mark Twain.
I would like to help you, but I don’t actually understand th epoints you raise. Could you create a post at powerpivotforum.com.au and post a small sample workbook showing the issue. It is very hard to help without this.
Matt, great work!
I have been trying to find some explanation for a confusion I have without any luck so far. Your post did help me clear up some clouds in my head. My fact (data) table usually contains (more than one) attributes [values] which are perfect candidates for isolating in a Dimension table. One example is “CustomerName”. The Fact does contain duplicates as well (and that’s another reason to rip them apart to reduce the file size). My approach/understanding is I try by “duplicating” the table, and removing extra columns, and then shortening by removing dupes. I also add “index” key after sorting them. However, when it’s time to create a relationship between the two, I can’t think of any way “how to replace values of “CustomerName in Fact” table with values of “Index from the Dimension” table. Could you please help me here?
Hey, Arthur. Couldn’t you merge the dimension table to the fact table (left outer join if you are in the fact table, CustomerName as the match), expand the index column that is now added to the fact table, and then remove the CustomerName column? Now you’ve got index number instead of each CustomerName.
Thanks. Credit goes largely to your book.?
Hi ,
Using Adventure Works database and an example in your book, Version 1 of the following example works. Is there any way to use the same example on the data table without creating a lookup table? I have tried Version 2 of the formula but clearly that does not work.
Many thanks
Aditi
Version 1 Count of Products that have some sales:=CALCULATE(countrows(Products),filter(Products,Sales[Total Sales Amount]>8000))
Version 2 Count of Products that have some sales:=CALCULATE(countrows(Sales),FILTER(SALES,[Total Sales Amount]>8000))
If you want version 2 to return the same result as version 1, but without using a lookup table, you could write this.
Version 3 Count of Products that have some sales:
=CALCULATE(distinctcount(Sales[ProductKey]),FILTER(values(SALES[ProductKey]),[Total Sales Amount]>8000))
Many thanks for your reply. i have a little doubt how are the tables Values(Sales[ProductKey] and Sales linked. Just checking if I have understood the logic right. So, here Values(Sales[ProductKey]) is working as the lookup table. Filter creates a row context in Row 1 of Values(Sales[ProductKey]) table and then the invisible calculate function wrapped around the calculated field [Total Sales Amount] propagates the filter from the table values(Sales[ProductKey]) to Sales Table ?
Aditi, that is an excellent and perfect explanation! You are truly on the way to becoming great at DAX. You have correctly identified all of the complicated concepts in this formula.
Good question. By default, if you need a sort column, then it becomes a 2+ Column lookup table and hence worth considering. Definitely if you have a large data table (millions of rows) and the slicer column is also large (say 20+ unique values) then I would prefer to create a lookup table. If he data is less than this it is really personal preference. I think I would create the lookup table anyway.
Thanks Matt for another great post.
As you mentioned a fundamental requirement of lookup table is a column of unique values. If there are two or more blank rows in that column then it would be impossible establish connection to the data tables. It is important to beware of the existence of duplicates and blanks in the primary key column.
Hi Matt,
Good article – particularly the explanation of why a single-attribute look-up table is sub-optimal.
However, your use of the term ‘junk dimension’ is a bit iffy. The concept comes from classic data warehouse design (Ralph Kimball specifically), and refers to a dimension that contains a collection of unrelated and non-hierarchic attributes. These are bundled together precisely to avoid single-attribute dimensions proliferating in a star schema model, gunking up the user experience. So it’s at best a related concept.
Thanks Richard for the clarification. Maybe my use of the word “learnt” is a bit of a stretch. I will make some adjustments. Appreciate your guidance.
Thanks Matt for this great blog.
My opinion is unless you are working on a homework problem or a very small data set, you will likely need to work with fact table and dimension tables all the times in real world. My company is not a data-driven company yet but we have multiple and multiple data tables and sets (dimension and fact).
Have a great day.
I agree Andrew, particularly if you are doing enterprise wide work. But some users coming from an Excel world may already have data in a flat table. Also it may make sense to create some lookup tables but leave other data as a single column in the data table.
Excellent explanations.
Right words just in time. Thanks!