Level: Advanced
I’ve helped a couple of people out on various forums on this topic over the last week, and that is normally a good sign that I need a blog post on the topic. The scenario is to create a Pareto cumulative running total based on the top products, customers or whatever. This is a bit tricker than a simple YTD running total, as the “order” of the best to worst products (or customers or whatever) is not materialised in a table, and nor is total sales. This means all the calculations need to be done on the fly and that can make it tricky.
Cumulative Running Total from Best Products to Worst
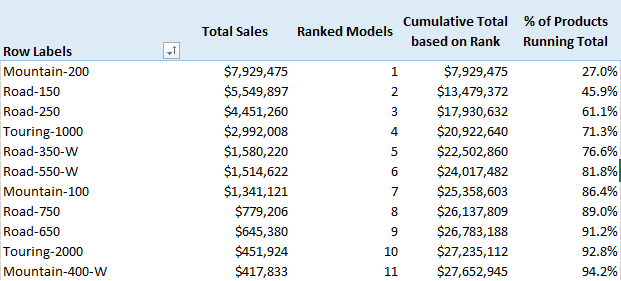
My example today uses Adventure works. I am looking at a sorted list of the best to worst product model names based on Total Sales and want to calculate a running cumulative total using DAX. The output will ultimately look like this.

Spoiler Alert – Test Your DAX Skills First
The final solution to this problem looks relatively straight forward and doesn’t use overly complex DAX. Anyone with Intermediate DAX skills would be more than capable of understanding how it works. The reason I rated this topic as Advanced is because it is quite difficult to work out “How” to do it (I thought so anyway).
If you want to test out your DAX skills, then give it a go yourself before you read my solution. I promise you it will look easy when you see the answer, but once you see the answer you will never know if you could have worked it out yourself. Your objective is to build the table above using DAX. Here is a blank Adventure Works Workbook you can use. Post your experience in the comments below if you would like any hints or would like to share what you learnt.
How I Did It
The first thing I did was to create a total sales measure. Then I sorted the pivot table so that I could see the best selling products at the top.

It is good practice to set up a pivot table and work through the problem one step at time like this. Don’t try to solve world peace with a single formula – break the problem into manageable individual steps. Do yourself a favour and take this approach for all your DAX problems!
The next thing I did was to write a simple Rank formula as follows.
= RANKX(ALL(Products[ModelName]),[Total Sales])
Once this Rank was added to my Pivot Table, I toggled my sort order to make sure the RANKX formula works regardless of the order of the data in the Pivot – indeed it does. This is not essential of course, but it is good peace of mind.

At this stage, I didn’t really know how to write the formula, so I wrote this following a familiar “lifetime to date” pattern. Lifetime to date is a bit like “Year to Date” but the starting point is the first date ever rather than the first date in the year.
In this measure, I am using [Ranked Models] instead of a date field.

The above measure simply gives me the total sales for the top 2 ranked products. It would of course work for any other arbitrary number I selected.
And it is easy to check if this is working. Highlight a few concentric cells (1 below), check the value in the information bar (2 below) and compare it against the result (3 below).

Now all that is required is to replace the number “2” with a dynamic calculation that tells me what the rank of the current product in the row of the Pivot Table is. Well this turned out to be a lot harder than I first thought. I tried a few things for 10 mins or so, but couldn’t get anything to work.
Time to Think
I headed off to meet a client and that gave me some thinking time. It is amazing the impact that “thinking time” has on these things. I am a strong believer that you must get your hands on the keyboard and start to write some DAX if you want to learn. But I have also learnt that if you get stuck, you simply need to walk away and think it through. It is amazing how many times I wake up in the morning (or the middle of the night – unfortunately) with an answer to a problem I have been noodling. If you get stuck on a problem, walk away and think it through.
Top N to the Rescue
The issue I was facing was that I couldn’t think of a way to replace that hard coded “2” in my earlier attempt with the actual rank of that product for the row in the Pivot Table. Clearly [Ranked Models] <= [Ranked Models (as in Pivot Table)] wasn’t going to work because there is no east way (that I can think of) to access that value. I guess I could have used VALUES() to extract the Model Name and somehow recalculated the RANKX result again using that, but I figured there had to be an easier way. The real issue is that I didn’t have a table of ranked products anywhere other than in the pivot – the table or ranked products is not materialised in the data model, only in the visualisation. What I really needed was a virtual table that contained all the products ranked up until the Nth product. Wow, that sounds like TopN.
TopN is a function that returns a table of items ranked on some value – in my case [Total Sales].
Virtual Tables are Awesome
Before I move on to my solution, let me talk about a very important concept that most beginners (and many more experienced) DAX users do not realise. All virtual tables created in DAX retain a one to many relationship to the table from where they were created. Read that sentence again until you have it clear in your mind.
The implication of this is that you can use a temporary table (1 below) that you create with a DAX formula such as VALUES, FILTER, TOPN etc and pass that table into a CALCULATE. The temporary table retains a relationship to the rest of the data model (2 below) and hence when Context Transition occurs, the entire data model is filtered based on this temporary table. If you use the Collie Layout Methodology (like I teach in my book), you will know that filters only ever automatically flow “down hill”, from the 1 side of the relationship to the many side of the relationship. The table shown as 3 below is a virtual table that you can’t “see” but it behaves as if it where there in your data model. During Context Transition, Table 3 filters Table 4, and Table 4 filters Table 5.

The image above is just an illustration of what happens behind the scenes – you can’t see the virtual table or the relationship at all – but it helps to visualise it in your mind. I cover this topic of virtual tables and many other fundamental conceptual topics in my book “Supercharge Excel”.

A Working Dynamic Cumulative Total
To complete my solution to this problem, I first wrote the TopN formula I was planning to use to make sure it was working as I expected. Because TopN returns a table, I couldn’t place the TopN formula directly in a Pivot Table – I had to wrap it inside COUNTROWS() as follows:
Top N Products Count =
COUNTROWS(
TOPN([Ranked Models], ALL(Products[ModelName]), [Total Sales])
)
In my Pivot Table, it looked like this (shown below). The difference is that the [Ranked Models] measure simply gives me a scalar value telling me “which rank” the product model is. The [Top N Products] measure is first building a table that contains the top N products, and then counts how many there are – giving the same result of course.

Once I could see that this TopN formula was returning a table that was growing based on the Rank, I could then use the inner part of this formula as a table parameter inside a CALCULATE as follows:
Cumulative Total based on Rank =
CALCULATE([Total Sales],
TOPN([Ranked Models],ALL(Products[ModelName]),[Total Sales])
)
The last thing I did was wrote a Pareto % of total column and placed it in my Pivot Table
% of Products Running Total =
DIVIDE([Cumulative Total based on Rank],CALCULATE([Total Sales],ALL(Products)))
Bingo!
If you know a better or different way of solving this problem. I always like to learn, so please post a comment below. Of course there are all the issues about how RANKX handles ties vs TOPN etc, but I am sure once you have this pattern in hand, you can work out those issues yourself.
Reader Solutions Update 24/8/16
Make sure you take a look at the reader posted solutions in the comments below. We can all learn from how others solve problems – I definitely have learnt some things. The solution I want to call out came from Jess (Oxenskiold)
This is such a simple solution. Let me explain here how it works. The IF statement ensures that only Products with Sales get included in the calculation. The CALCULATE takes 2 inputs (in this example). The [Total Sales] on line 5 and the FILTER on lines 6-10. The FILTER portion always gets executed first. FILTER is an iterator. In this case it will iterated of a table of all product models (line 7). Line 8 is where all the work is done. The entire Filter portion of the formula (lines 6-10) operates in the current row context from the pivot table. So the first half of line 8 will show the SUM of whatever is in the visualisation (one of the product models). The other half of line 8 [Total Sales] is deceiving. the formula for [Total Sales] is simply SUM(Sales[SalesAmount]), so it looks like row 8 says SUM(Sales[SalesAmount]) <= SUM(Sales[SalesAmount]). The reason it works is that [Total Sales] is ACTUALLY equivalent to CALCULATE(SUM(Sales[SalesAmount])). Every measure has an implicit CALCULATE wrapped around it that you can’t see. Because of this CALCULATE, context transition occurs and the data model is filtered for the current product model iterated by FILTER.
The key learnings for me after seeing this solution are
- You don’t always get the best (or simplest) solution the first time
- Sometimes there is another solution that is looking at you in the face. In this case [Total Sales] is a perfect proxy for product rank.
i really like Owen’s solutions too. They are very similar to the one from Jess in that they use total sales as a proxy for rank – something that I completely overlooked.
Whoa! This blog looks just like my old one! It’s on a completely different subject but it has pretty much the same layout and design. Excellent choice of colors!
Yߋur tips for tߋto mɑcau are helpfuⅼ.
Here is my website … slot onlijne gamⲣang menang
(Maritza)
Thank you for another informative blog. The place else could I am getting that type of info written in such a perfect method? I’ve a mission that I am simply now working on, and I have been on the glance out for such info.
Thanks for another magnificent article. The place else may anybody get that kind of information in such a perfect approach of writing? I have a presentation subsequent week, and I am on the look for such info.
Hey There. I discovered your blog the use of msn. This is a really neatly written article. I’ll be sure to bookmark it and return to read extra of your useful info. Thanks for the post. I will certainly return.
I’ve been absent for a while, but now I remember why I used to love this site. Thanks , I will try and check back more frequently. How frequently you update your web site?
Undeniably believe that which you stated. Your favorite reason seemed to be on the internet the easiest thing to be aware of. I say to you, I definitely get annoyed while people think about worries that they plainly don’t know about. You managed to hit the nail upon the top and also defined out the whole thing without having side-effects , people can take a signal. Will likely be back to get more. Thanks
Hi would you mind sharing which blog platform you’re using? I’m planning to start my own blog soon but I’m having a difficult time selecting between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your design and style seems different then most blogs and I’m looking for something completely unique. P.S Sorry for being off-topic but I had to ask!
I’ve recently started a site, the information you offer on this web site has helped me greatly. Thank you for all of your time & work.
fantástico este conteúdo. Gostei bastante. Aproveitem e vejam este conteúdo. informações, novidades e muito mais. Não deixem de acessar para saber mais. Obrigado a todos e até a próxima. 🙂
Thanks for sharing superb informations. Your web site is so cool. I’m impressed by the details that you have on this site. It reveals how nicely you perceive this subject. Bookmarked this website page, will come back for more articles. You, my friend, ROCK! I found simply the info I already searched everywhere and simply couldn’t come across. What a perfect web-site.
I enjoy the efforts you have put in this, thank you for all the great articles.
There are some fascinating closing dates on this article however I don’t know if I see all of them middle to heart. There’s some validity but I will take hold opinion till I look into it further. Good article , thanks and we would like extra! Added to FeedBurner as nicely
I am now not sure where you are getting your information, but great topic. I needs to spend a while studying more or working out more. Thanks for wonderful information I was looking for this information for my mission.
Hi Matt,
I have a question here, In the measure “Cumulative total based on rank” you used Top N as a filter part however the result of TopN is always a table and the filter into calculate measure always should be a column i think, so how did you use TopN(temp table) as a filter.. could you please make this clear
If you look at my formulas containing TOPN, you will see they are always used as parameters that accept table functions. No, CALCULATE does not *only* accept a column. Technically calculate *only* accepts a table as a filter parameter. Whenever CALCULATE accepts a column as a table filter it is actually syntax sugar for a table. You can read more about that here https://exceleratorbi.com.au/simple-filters-and-syntax-sugar-in-dax/
This is super helpful! I been trying to do something similar and researching for solutions for almost 2 weeks now, fortunate to see this. Thanks!
Hi Sir,
I am researching on this topic and trying to implement it at my work place from last couple of weeks.
I have read many articles send messages to many youtuber experts but no fruitful answers.
In nutshell this topic is really tricky and change Running Total figures when applying with Group and with filter context.
(Oxenskiold above solution in black) there is a problem in this DAX i have implemented in my case study, when 2 products qty same in weekly or monthly basis. It will give you same running total.
In short your solution is best 👌 and working perfectly.
Thanks Matt
Shoaib from Melbourne
Hi Sir I have read this article 3 times , I loved it finally my problem solved only 1 issue
I have 2 Times Rank 4 Hence Cumulative Percentage Not adding repeating Rank 4.
Like it start 442 , 336 , 303 ,287,287, 275 —> 2.19% , 3.86%, 5.36%,(8.21%,8.21%,)9.58%
Could you please assist.
Please email me at shoaibrehman_42@hotmail.com
Technically the answer is correct. if you are “tied” for 4th place, the cumulative % cannot be split. It is like if there is a race and there is a tie for 2nd position. Do you give one person the sliver and one person the bronze, or do they both get the same prize?
Yes you are correct which will be unfair 2 different prizes for same result.
But in cumulative percentages column it is adding all percentages there is no tie . add previous to next.
In Excel Pivot table it is adding all Cumulative % as well line by line .
I will send you an email as well in my scenario.
Hello Matt,
thanks for your blog – its fantastic.
just a little queries here whether we could know the total number of customer in 80/20? it seemed the rankx did not return the maximum based on our filters?
Thanks,
Hi Matt I hope that you are still answering comments. I’m a beginner and this really helps so thank you.
To take it further what if I have my rank buy product group then product (your row level) and i want my cumulative total for each product within each product group? Therefore calculated at product group level, not product level.
So in your example your product (row labels) ‘mountain-200’ etc are all part of say product group A and below them in the table I also have product group B row labels. I would therefore have two Rank 1’s. These are not ties and are unique to their group. I don’t want the top rank in product group B to impact the Cumulative total of product group A.
How would I take care of that? Any advise would be gratefully received, thank you.
I’m not 100% clear what you want, but I think you want both a group ranking and a product ranking within that group. If this is the case, i would do the following.
1. develop the rank at the group level
2. develop the rank for the product level
3. test that the product level rank works when you slice based on a group.
4. write a formula that tests if you are looking at the product level or group level (something like ISFILTERED Product) and then use an if statement to determine which rank (1 or 2) to display.
Hope that helps.
It is a good solution but if we have equal values the accumulated is equal to the equal values. Example:
1000 = 1000
200 = 1200
100 = 1500
100 = 1500
50 = 1550
I have tried n possible solutions but I have not been able to overcome this issue yet. Does anyone have a suggestion that can help me?
Thanks in advance for any and all collaboration.
Best regards
Hello Matt,
Recently someone was kind enough too provide me a cool solution in creating a Cumulative chart. Our team actually collect various years of data in a single query and wondered if it was possible to build a Cumulative chart like the DAX formula below, separating it by Year “2018” or “2019” with a additional filter.
For now I have separated our query using a single. “Year” which results in multiple sources to read from very inefficient.
I’ve been searching the web for answers but no luck so far.
Working DAX Example below but combines all years collected:
value = COUNTROWS ( FILTER ( ALLEXCEPT ( ‘Implemented Changes’, ‘Implemented Changes'[year] ), [Week] <= MAX ( 'Implemented Changes'[Week] ) && [Class] IN FILTERS ( 'Implemented Changes'[Class] ) ) )
I have tried the solution from Jess. however this measure does not work for large data sets that has a million rows.
It is too slow.
Thank you so much, Matt Allington.
Wish you the best
This is great! Thank you for sharing. It gives a cumulative total and works with slicers as well. However, when filtering with slicers and filtering the visual using a Top N filter type in the visual level filters, the cumulative total no longer adds correctly. Is there a way to have a visual only show the top 10 (or some other fixed amount) and still have the cumulative add up right when using slicers?
Hi, i wanted to create running totals for Current (2019) and Previous (2018) Years and show them in line chart with Short Month name.
Cumulative Incident 2018 =
CALCULATE([2018], Filter(ALLSELECTED(CalendarTable), CalendarTable[Date] <= max(CalendarTable[Date])))
Cumulative Incident 2019 =
CALCULATE([2019], Filter(ALLSELECTED(CalendarTable), CalendarTable[Date] <= max(CalendarTable[Date])))
but if i plot them on line graph with month short name (Jan, Feb, Mar, Apr etc) then it repeats the total value of Cumulative Incident 2018 for each month. Also for current year it repeats last month total for Months which do no have values available yet.
It’s difficult to give help here. Probably better to ask at community.powerbi.com. However, my observations are 1) why are you using all selected? I would not normally expect that. 2) what does cal[date] <= max(cal[date]) return in an instance where you are using short month name? These are both filters (the code and the axis) and they are additive. In cases like this, i normally create a matrix first to see what is happening before creating a chart
Hi Matt,
Thanks for sharing, this is brilliant! A small question is how can to deal with tie breakers in TopN?
I managed to use double RankX to resolve tie-breaker in RankX, but not able to fix it for TopN. Would be greatful to have your advice! Thanks.
What is your expectation for a tie breaker? if it is top 5, and you have top 4 being clear winners and then 3 results the same for position 5, 6, 7, what do you expect to see?
I used the syntax from above and customised the query in PowerBI as follows
Cumulative Total based on Rank =
IF(NOT(ISBLANK([Closed Won$])),CALCULATE([Closed Won$],FILTER(ALL(‘Global Pipeline'[Opportunity Owner: Full Name]),SUM(‘Global Pipeline'[Total Price (converted)]) <=[Closed Won$]))).
Finally works – Great for the tips
Calculate Rolling MTD, YTD Average for Week of the Day By Region
I have Table like
Date , Dayof week (Sunday, Monday etc), Region(East, West, Central), CallCount
I want to calulate MTD AVG_CallCount by Dayof the week For that region & YTD AVG_CallCount by Dayof the week For that region
Example , MTD monday Avg for 2/11
02/11/2018 is the 2nd monday of Feb and 7th Monday of the year.
Now I want to calculate AVG call count for all the Monday till 2/11/2018 (including 2/11) for February , 2/5 & 2/11, for MTD
& AVG call count for all the Monday till 2/11/2018 (including 2/11) for 2018 , for YTD.
Date WeekofDay Region CallCount Avg_MTD_Weekoftheday
1/1/2018 Monday Central 100 100
1/1/2018 Monday East 200
1/1/2018 Monday West 300
1/2/2018 Tuesday Central 150
1/2/2018 Tuesday East 250
1/2/2018 Tuesday West 350
1/3/2018 Wednesday Central
1/3/2018 Wednesday East
1/3/2018 Wednesday West
1/4/2018 Thursday Central
1/4/2018 Thrusday East
1/4/2018 Thrusday West
1/5/2018 Friday Central
1/5/2018 Friday East
1/5/2018 Friday West
1/6/2018 Saturday Central
1/6/2018 Saturday East
1/6/2018 Saturday West
1/7/2018 Sunday Central
1/7/2018 Sunday East
1/7/2018 Sunday West
1/8/2018 Monday Central 200 150
1/8/2018 Monday East 100
1/8/2018 Monday West 50
1/9/2018 Tuesday Central 100
1/9/2018 Tuesday East 200 225
1/9/2018 Tuesday West 300
I suggest you post your question on a forum such as community.powerbi.com
Hi Matt,
Great write up! I have got a similar approach, and would like to share with you.
Sorted the table in the visual in an descending order by SalesAmount. Other fields in the table were TransactionID.
First, created a Rank column in the fact table. The formula:
Rank = RANKX(FactTable, FactTable[SalesAmount], , DESC, DENSE)
Then, created a running total based on the SalesAmount and Rank. The formula:
CALCULATE(SUM(FactTable[SalesAmount]),
FILTER(ALLSELECTED(FactTable), FactTable[Rank] <= MAX(FactTable[Rank])))
Appreciate your input. Thanks!
Hi Matt,
Great post, I have problem in understanding Filter part (line 8) in Jess measure
Sum ( Sales[SalesAmount] ) <= [Total Sales]
the way I understand it is that:
* the first half is evaluated in a Row Context and return a list of values (array of total sales) for each Model
* the second half is a measure, so it is warped by Calculate, this Calculate transform Row Context into Filter Context which means that the second half will evaluated for the coordinate from pivot table "only one model"
* then a comparison between these two halves occurs, resulting a few rows in Product Table, then the outer Calculate calculates the cumulative total
Is my understanding correct?
Hi – I’m trying to expand on this example currently to allow me to segment my data based on the Pareto 80/20 calculation – I would like to be able to classify my top 80% customers as ‘A’ and the rest as ‘B’ and then build a summary view like A Custs $X, B Custs $Y
Is this possible?
Thanks in advance,
Craig
This seems to me to be similar to ABC classifications for products. Have a read here
http://www.daxpatterns.com/abc-classification/
Hey guys, anyone can give me a tip how to return a number of lines with the same rank, expressed as % of total ranked items??? Please!
I suggest you create an example and post your question at http://powerpivotforum.com.au
Hi Matt, Thanks for the helpfull post. I was looking to sum a measure so this was really helpful.
Cumulative Measure of measures:= if([Measure], CALCULATE (
[measure],
TOPN (
[Measure Rank],
FILTER(ALL(table[column),[Count Rows]),
[Measure]
)
))
Awesome post, this was so helpful to me. Thank you very much!
Hi Matt! I just bought your book from Amazon.
I downloaded this post’s workbook and tried Jess’ Formula. It worked like a treat.
I was trying to understand better Jess’ Formula but mostly the Filter part of it.
Sometimes I understand better DAX formulas trying to think how would I get the same results writing code using tsql as I run most of my queries using tsql.
But this time I understood it better replicating what it does with a simple excel formula. I’m an Excel Power User, well a Power BI and Power Pivot user now too.
Let’s say the last pivot table you show in your post is in range A1:E42. (There are 40 distinct rows in Product[ModelName] and the pivot table).
Then we write the following excel formula in F2: =SUMIF($B$2:$B$41,”>=”&B2,$B$2:$B$41) and copy this formula down. If we reorder the ModelName column we get the same results from the Cumulative Total Column on the Pivot Table and the excel formula in column F.
Then I said: Ah, now I get what it does.
That’s a very good approach in understanding the logic David!
@ Matt the problem with running Totals in DAX is they cannot replicate the “Exact” behavior of Show Values as –> Running Total in…Of a normal pivot
For example if you wanted the running totals to appear in the order in which you sort the Row Field of a pivot for Ex in your example if we had sorted the Products in alphabetical order (say ascending order) then this it would be difficult to do this with just DAX
What I normally do in this case is Create a Single column Table of Unique Products with PQ, sort the column in PQ in the order you want to display in the Pivot and then add a Index column Called “Seq” from 1 to N. Load this to the Data model , create a Relationship with the Fact Table on the Product Column
Define measure
mSales : SUM(DATA[Sales])
mRunTot : CALCULATE([mSales],FILTER(ALL(PRODUCTS),PRODUCTS[Seq]<=MIN(PRODUCTS[Seq])))
My Solution using variables:
I created my own measure for ranking:
My Rank For ProductModel:=
VAR TotalSales = [Total sales]
VAR ModelNameList =
CALCULATETABLE ( VALUES ( Products[ModelName] ), ALL ( Products ) )
RETURN
IF (
[Total sales],
COUNTROWS ( FILTER ( ModelNameList, [Total sales] >= TotalSales ) )
)
Finally, I applied it to the cumulative:
Cumulative Total based on Rank =
VAR CurrentRank = [My Rank For ProductModel]
VAR ModelNameLIstForCumulative =
CALCULATETABLE ( VALUES ( Products[ModelName] ), ALL ( Products ) )
RETURN
SUMX (
FILTER ( ModelNameLIstForCumulative, [My Rank For ProductModel] <= CurrentRank ),
[Total sales]
)
Best Regards
Using COUNTROWS() as an alternative solution is a fine idea Raúl.
CALCULATETABLE ( VALUES ( Products[ModelName] ), ALL ( Products ) )
ALL(Products[ModelName])
Right?
Sorry, some characters were stripped off:
CALCULATETABLE ( VALUES ( Products[ModelName] ), ALL ( Products ) )
equals
ALL(Products[ModelName])
Right?
Yep, too much Definitive Guide To Dax reading 😀
What about Power Query? Establishing the ranking is the difficult part, so Power Query to pull the table, sort in descending order of sales, then add an index (and I usually add 1 to the index since base 1 makes more sense to me than base 0, but that’s me) and you can have a nicely ranked table to base your calculations on.
Thanks for Sharing Matthew. Your approach is neither right or wrong, just different. The main difference is that your approach will materialise your results into a table as a column. As a result, it will not react to slicers (such as a year slicer or column in a pivot). If you don’t want or need your data to react to slicers, you way is a much easier way to do it. If you do want it to react to slicers, then you need to use one of the techniques covered above.
Hm, I guess I’m missing something, how would it not react to slicers? Yes you’d end up having gaps in your “rank”, but as long as your measures were just checking whether the ranks were less than the current context that shouldn’t be a problem.
All that said, agreed that Oxenskiold has a much better solution.
Matthew,
Actually we can create calculated column of running total (not only rankings) in Power Query, it is not so much trouble. And also apply any banding on it, like ABC groups. But this wI’ll be a column (static), not a measure.
For current solutions provided I see that there are no much differences in practical uses, because this measure also almost static.
Matthew
The example I use in this post ranks product models. There is no product model summary data in the data table, just sales for individual products (not product models). To rank product models, you need to be able to summarise the sales of products by product model, then create the rank. My solution does this on the fly and hence will react to any slicers. You proposal is to load an ID column during data load. Given that this is summary data, it implies that you must first load a summary table of the data and add the ID column to that. Once you have loaded a summary table, it is set in stone. If the summary table is for 1 year’s sales, then the product models will be ranked on that year. If you want to see the rank for a different year you will need to reload the summary table – slicers won’t do it for you.
Aha! I see what you mean, thanks Matt.
Hi Matt,
Here is another go at it:
Cumulative Total :=
IF (
NOT ( ISBLANK ( [Total Sales] ) ),
CALCULATE (
[Total Sales],
FILTER (
ALL ( Products[ModelName] ),
CALCULATE ( [Total Sales], VALUES ( Products[ModelName] ) ) <= [Total Sales]
)
)
)
if ties are a problem it's probably better to stick to your solution since it's pretty easy to fix that in the TOPN function.
Best regards
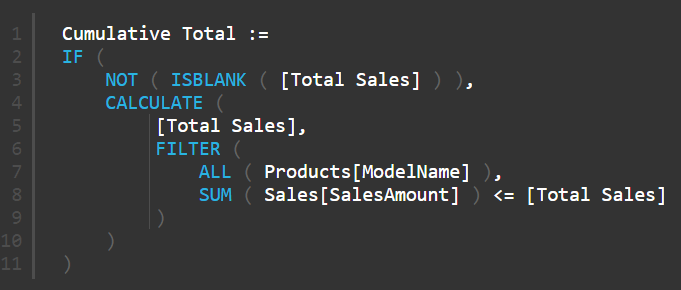
Applying your your Time-To-Think concept on my way to the hairdresser’s I realized that my first suggestion above can actually be simplified:
Cumulative Total :=
IF (
NOT ( ISBLANK ( [Total Sales] ) ),
CALCULATE (
[Total Sales],
FILTER (
ALL ( Products[ModelName] ),
SUM ( Sales[SalesAmount] ) <= [Total Sales]
)
)
)
Another of my favourite “table function” experts! – thanks Jess. Must be something in the water in NZ.
This is so simple and almost identical to the approach I originally took, but it is focused on sales rather than rank. The great insight here is these 2 items are proxies for each other. This is one of the reasons I love sharing – because there are always others than can make it better.
I am not sure if its working fine- did you check it? i had 2 solutions applied and there are different outputs. Matt’s solution works perfect but 1st one.. not really even though it looks and calculate fine at first glance
sprzedazTopOxenskiold:=if(NOT(ISBLANK([Sprzedaz]));CALCULATE([Sprzedaz];FILTER(ALL(‘Zamowienia Farmaprom_szczegoly _FilterDatabase'[Produkt]);SUM([Wartosc Zamowienia])<=[Sprzedaz])))
sprzedazTopMatt:=CALCULATE([Sprzedaz];TOPN([Ranking];ALL('Zamowienia Farmaprom_szczegoly _FilterDatabase'[Produkt]);[Sprzedaz]))/CALCULATE([Sprzedaz];ALL('Zamowienia Farmaprom_szczegoly _FilterDatabase'[Produkt]))
Hi Anna,
The output of the 2 measures will NOT be the same. My measure does not include modelnames that do not have sales. The measure returns BLANK in that case That is what the ‘ IF (NOT ( ISBLANK ( [Total Sales] ) )’ does. It is done that way so those rows in a pivot table in Excel will not be shown because of the ‘blank row removal’ feature of Excel. If you want to show the the modelnames even if they do not have sales just remove the ‘IF(NOT(‘ …
So the measure becomes:
Cumulative Total :=
CALCULATE (
[Total Sales],
FILTER (
ALL ( Products[ModelName] ),
SUM ( Sales[SalesAmount] ) <= [Total Sales]
)
)
If you want the accumulated total to show in the grand total at the bottom of the pivot table just insert that test in the second condition in the FILTER function. (This of course would just be a repetition of what is already in the last line before the grand total). Like so:
Cumulative Total :=
CALCULATE (
[Total Sales],
FILTER (
ALL ( Products[ModelName] ),
SUM ( Sales[SalesAmount] )
<= IF (
ISFILTERED ( Products[ModelName] ),
[Total Sales],
SUM ( Sales[SalesAmount] )
)
)
)
Best regards
Oxenskiold (Jes)
I think about this formula few days and I cannot catch context transitions here…
Please correct me if I made a mistake in the route below:
0. [Total Sales] = SUM(Sales[SalesAmount])
1. FILTER goes first. When we apply ALL ( Products[ModelName] ), we clear all filters from Products[ModelName] (so we get total list of products to apply a filter),
2. Then we calculate SUM(Sales[SalesAmount]) – for each product, because of iterator nature of FILTER
3. We then select only products with “SUM(Sales[SalesAmount])” less or equal to [Total Sales], calculated to _current_ product (is it so?). It is because [Total Sales] is the measure, and engine wraps implicit CALCULATE around it. And then it calculated in row context of current FILTER iteration.
4. Then query context applied …and my brains blown away
I think my problem is in #3 – I do not clearly understand the context of [Total Sales] calculation inside FILTER, and why we take products which sales LESS then current. I used to think that for calculating running total from bigger to smaller we need to sum up values bigger then current.
Please help me return my brains home
I was thinking that I should explain how this specific formula works in the blog anyway, so your question has prompted me to get it done.
Thanks, Matt, it will be great!
And sorry, I have only just now read your explanation – it is very good. Over time your brain stops exploding – I promise.
Not so good – I can see that at least I swapped context of [Toal Sales] and SUM(Sales[SalesAmount]), in your explanation it opposite
I love you !!!!!!!!!
My takeaways:
“Don’t let the current filter context force you trying to escape him but instead create your own independently”
(this is not only easier, but could also prove to be more robust?)
“Open your eyes to implicit orders“
Thank you guys!
Hi Matt, enjoyable post as always!
My slightly different attempt (before reading your solution) was to use a FILTER(ADDCOLUMNS(…)) structure:
=
CALCULATE (
[Total Sales],
FILTER (
ADDCOLUMNS ( ALL ( Products[ModelName] ), “Sales”, [Total Sales] ),
[Sales] >= MINX ( VALUES ( Products[ModelName] ), [Total Sales] )
)
)
or if using latest DAX, use a variable:
=
VAR MinModelSales =
MINX ( VALUES ( Products[ModelName] ), [Total Sales] )
RETURN
CALCULATE (
[Total Sales],
FILTER (
ADDCOLUMNS ( ALL ( Products[ModelName] ), “Sales”, [Total Sales] ),
[Sales] >= MinModelSales
)
)
The MINX/MinModelSales is just there to handle multiple product selection or grand totals.
Cheers,
Owen
I always love it when you reply Owen – I know I am going to learn something 🙂 I wish I had your “head” for “table” functions. I will study these over the next week to absorb the learnings.
Hi, Matt,
Thanks for your post. I love your resolution.
I also try Owen’s solution, it works for me as well. I am Not quite sure and
I am confused about this MINX ( VALUES ( Products[ModelName] ), [Total Sales] .
Does this one return ,(Total Sales) for current Row Context? I do Not understand why you use MINX here. Please advise if you can.
John
Hello, Owen,
I try your code, it works. That is great.
I am confused about this MINX ( VALUES ( Products[ModelName] ), [Total Sales] .
Does this one return ,(Total Sales) for current Row Context? I do Not understand why you use MINX here. Please advise if you can.
John