Learn how to remove duplicates keep the last record on power query.
Today I was helping a customer with a problem that seemed quite simple on the surface. She had a data table containing historical customer sales orders (each customer has many orders on different dates). The objective was to filter this table in Power Query and just load one record for each customer – the one that was the last order date. To illustrate the problem more clearly, I have adapted the scenario using the Adventure Works database so you can remove duplicates keep the last record on power query.
Adventure Works Example
The Sales table contains all the historical sales transactions by customer (identified by CustomerKey) and each transaction has an Order Date. The objective is to filter this table in Power Query so as to keep only the last entry for each customer (the last entry is the most recent order date). At the first instance, the solution seems to be simple. In Power Query, you would think that you simply:
- Sort the table by Order Date in descending order.
- Select the customer key column and then remove duplicates.
But when you do this in Power Query, it does not work as expected. As you can see in the Sales table below, each customer has many transactions with different order dates.
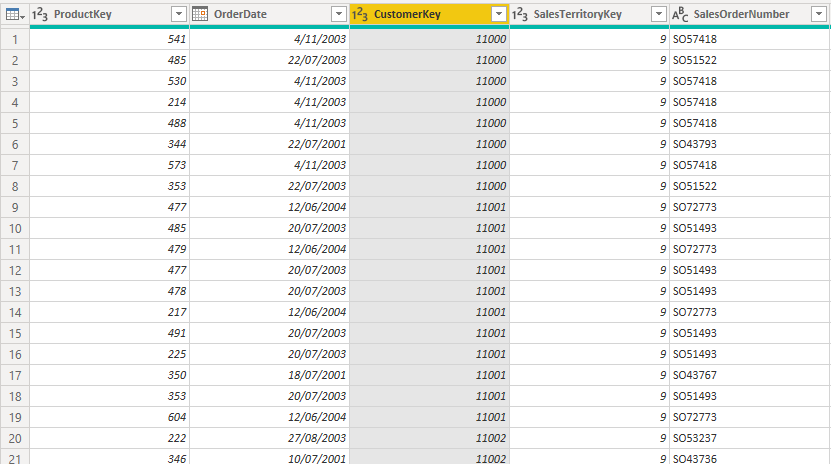
In Power Query, I sorted by OrderDate descending, then removed duplicates as shown below.
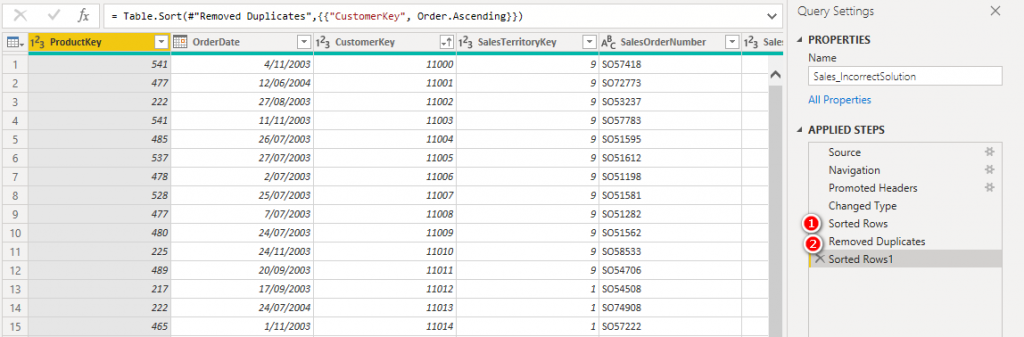
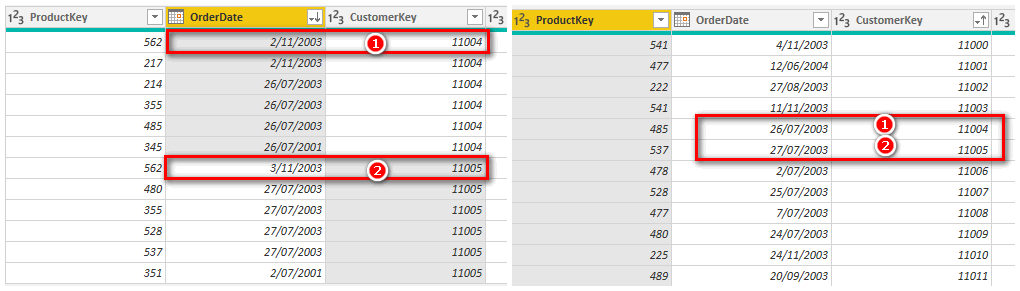
But the solution is not correct – the order dates for some of the customers are actually not the last orders. The table on the left below shows the original data sorted by OrderDate for each customer. The table on the right below shows the results from Power Query. If you compare the full data on the left with the Power Query results on the right, you can see that PQ has returned the wrong order date for some customers.

Why Doesn’t it Work?
I can’t say that I have a deep technical understanding of the problem, but I do have a conceptual understanding. When you select “sort column”, it is reasonable to expect that the entire table is sorted before proceeding to the next step. In reality, it is only the data that is loaded in memory that is sorted. The remaining data on disk is not included in the sort. Power Query also uses a concept called “lazy evaluation”. In short this means that if you add a step in the code, and that step is not technically needed to produce the final result, then that step is actually never executed (even though it is there in the instructions) – weird I know, but very efficient.
Table.Buffer to the Rescue
Before I share this solution, let me point out there are other ways to solve the problem, specifically using group by. However, the purpose of this article is to broaden readers understanding of Power Query and introduce the table.buffer function.
I am pretty sure I learnt this tip from Imke Feldman at The BIccountant (or possibly Chris Webb). Both are absolute wizes at this stuff. To solve the problem you will need to get in and make some manual changes to the M code. To do this, first make sure you turn on the formula bar. Go to the View menu and select “formula bar”.
When I click on the step that sorts the table (desc) by OrderDate, the M code was as follows:
![]()
To solve the problem, I need to force Power Query to load all the data into memory, forcing the sort to be completed now before proceeding. All I did was to wrap the line of code above inside the Table.Buffer( ) function as shown below.
![]()
The rest of the steps remain the same. The Table.Buffer( ) function forces the entire set of data to be loaded into memory after sorting and the hence the next step of removing duplicates works correctly on the entire data set.
The resulting table looks as follows:

These results are now correct as you can see in the table below. The OrderDate (Incorrect Solution) column is the result without using Table.Buffer( ) and the OrderDate (Correct Solution) column is the result of using Table.Buffer( ). You can see several customers have different results. The correct result can be manually validated against the raw data.

Here is the sample workbook and the source data that I used in this blog post.
The role of SEO is to enhance the visibility and ranking of a website or webpage in the natural results of search engines like Google, Bing or Yahoo! Search Engine Optimization (SEO) is an essential aspect of any successful online business strategy.
You always manage to tackle difficult subjects with such grace and insight.
Social media optimization includes sharing relevant and engaging content on social media channels, optimizing the social media profiles, and interacting with the audience.
buy coke in telegram cocain in prague fishscale
buy drugs in prague high quality cocaine in prague
Greetings! I’ve been reading your weblog for a while now and finally got
the courage to go ahead and give you a shout out from Huffman Texas!
Just wanted to mention keep up the good work!
With the vast number of websites on the internet, it is essential that the site ranks high on the SERP to gain maximum visibility. In conclusion, SEO is a valuable tactic that businesses must adopt in their online marketing strategies.
บทความนี้ น่าสนใจดี ครับ
ผม ไปเจอรายละเอียดของ เรื่องที่เกี่ยวข้อง
สามารถอ่านได้ที่ Jolie
น่าจะถูกใจใครหลายคน
มีตัวอย่างประกอบชัดเจน
ขอบคุณที่แชร์ คอนเทนต์ดีๆ นี้
จะรอติดตามเนื้อหาใหม่ๆ
ต่อไป
This data can inform businesses about their content strategy, audience targeting, and optimization techniques, helping them to improve their online performance and achieve their business goals.
The goal of keyword research is to identify the terms and phrases that users search for, and then use them strategically in content and metadata.
With tools such as Google Analytics, you can track your website traffic, user engagement, and other metrics that can help you optimize your website for better results.
Great beat ! I wish to apprentice while you
amend your website, how could i subscribe for a blog
site? The account helped me a applicable deal. I were tiny bit acquainted of this your broadcast provided
vibrant clear concept
Pretty! This was an incredibly wonderful article. Many thanks for providing these details.
출장이 필요할 때, 믿을 수 있는 파트너를 원하신다면 출장마사지가 함께합니다.
buy cocaine in telegram coke in prague
Great post. I was checking continuously this blog and I’m impressed!
Extremely useful info specially the last part 🙂 I care
for such information a lot. I was seeking this particular info for a
long time. Thank you and best of luck.
Fantastic goods from you, man. I’ve understand your stuff previous to and you’re just too excellent. I really like what you have acquired here, certainly like what you are saying and the way in which you say it. You make it enjoyable and you still take care of to keep it smart. I cant wait to read much more from you. This is really a great website.
Thank you for the auspicious writeup. It in fact was a amusement account it.
Look advanced to far added agreeable from you! By the way,
how can we communicate?
Useful information. Fortunate me I found your website
accidentally, and I’m stunned why this twist
of fate did not happened earlier! I bookmarked it.
Everything is very open with a precise explanation of the challenges.
It was really informative. Your site is very helpful.
Many thanks for sharing!
เนื้อหานี้ มีประโยชน์มาก
ครับ
ดิฉัน ไปเจอรายละเอียดของ เรื่องที่เกี่ยวข้อง
ซึ่งอยู่ที่ รีวิว betflik85 ล่าสุด
สำหรับใครกำลังหาเนื้อหาแบบนี้
เพราะให้ข้อมูลเชิงลึก
ขอบคุณที่แชร์ ข้อมูลที่มีประโยชน์ นี้
และอยากเห็นบทความดีๆ
แบบนี้อีก
Good day I am so happy I found your blog page,
I really found you by error, while I was researching on Bing
for something else, Regardless I am here now and would
just like to say thank you for a marvelous post and a all round
thrilling blog (I also love the theme/design),
I don’t have time to look over it all at
the minute but I have book-marked it and also added your RSS feeds, so when I have time I
will be back to read much more, Please do keep up the excellent
work.
Regards for all your efforts that you have put in this. Very interesting information.
Look into my page http://Minlove.biz/out.html?id=nhmode&go=http://www.daiko.org/cgi-def/admin/C-100/d-channel/yybbs.cgi%3Flist=thread
Hello there! This post couldn’t be written any better! Looking through this article
reminds me of my previous roommate! He constantly kept preaching about this.
I’ll send this information to him. Pretty sure he’s going to have a
great read. Thank you for sharing!
Valuable information. Fortunate me I found your website accidentally, and
I am surprised why this accident didn’t came about in advance!
I bookmarked it.
Great blog here! Also your website loads
up very fast! What host are you using? Can I get your affiliate link to your host?
I wish my website loaded up as quickly as yours lol
Slotnya cocok buat support.
하루의 피로를 풀고 싶으신가요? 저희 출장마사지 서비스로 집이나 사무실에서 편안한 휴식을 즐겨보세요! 고객의 편안함과 건강을 최우선으로 생각하며 맞춤형 힐링 서비스를 제공합니다.
You’re so awesome! I don’t believe I have read a single thing like that before. So great to find someone with some original thoughts on this topic. Really.. thank you for starting this up. This website is something that is needed on the internet, someone with a little originality! 👉 Watch Live Tv online in HD. Stream breaking news, sports, and top shows anytime, anywhere with fast and reliable live streaming.
I’ve been surfing on-line more than 3 hours these days, yet I bby
no means found any fascinating article like yours.
It is prety price sufficient for me. In my opinion, if all webmasters and
bloggers made jst right conntent matetial as you did, the net might bee a lot more helpful than ever before.
my website จัดดอกงานศพ
You made some really good points there. I looked on the net for additional information about the issue and found most people will go along with your views on this website.
You actually make it appear so easy along with your presentation however I
to find this matter to be actually somethimg which I think I
ight by no means understand. It seems too complex and extremely vast for
me. I am taking a look ahead for your subsequent post,
I’ll attempt to get the hold of it!
Also visit my homepage :: new York
Having read this I believed it was very enlightening. I appreciate you finding the time and effort to put this short article together. I once again find myself personally spending a lot of time both reading and leaving comments. But so what, it was still worthwhile!
my web page: http://Fen.Gku.An.GX.R.Ku.Ai8.Xn–.Xn–.U.KMeli.S.A.Ri.C.H4223@www.Trackroad.com/conn/garminimport?returnurl=https://Familylawyernycgroupp.com/practice-areas/grandparents-rights/
For most recent information you have to pay a visit the web and on internet
I found this web page as a best web page for most up-to-date updates.
My website: Cms.Bytesinmotion.com
Do yoou mind if I quote a few of your posts as long as I provide credit and sources back to your blog?
My website is in thhe exact same area off interest as yours and my visitors would definitely benefit from a lot off the information you
provide here. Please let me know if this alright with you.
Cheers!
Allso visit my webpage – รับจัดดอกไม้หน้าโลงศพ
Just what I was looking for. 👉 Watch Live Tv online in HD. Stream breaking news, sports, and top shows anytime, anywhere with fast and reliable live streaming.
Hi there! This is my first visit to your blog! We are a team of volunteers and starting a new initiative in a community in the same niche. Your blog provided us beneficial information to work on. You have done a wonderful job!
Hurrah! Finally I got a website from where I can really obtain useful facts regarding my study and knowledge.
What’s Taking place i am new to this, I stumbled upon this I’ve discovered It absolutely helpful and
it has aided me out loads. I am hoping to contribute & assist different users like its aided me.
Great job.
https://execumeet.com/
Technical factors: Technical factors, such as website structure, meta tags, sitemaps, and schema markup, also influence your ranking. Ensuring that your website follows best practices for technical SEO can improve your visibility and ranking.
Search engine optimization (SEO) is the process of optimizing a website to rank higher on search engine results pages (SERPs). The importance of SEO cannot be overstated, and without it, a website might as well not exist.
Ridiculous quest there. What occurred after? Thanks!
https://qualitypashmina.com/
It’s actually a great and helpful piece of information. I am satisfied that you shared this helpful info with us. Please stay us up to date like this. Thank you for sharing.
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone to do it for you? Plz respond as I’m looking to construct my own blog and would like to know where u got this from. thank you
Hey there, I think your website might be having browser compatibility issues. When I look at your blog site in Firefox, it looks fine but when opening in Internet Explorer, it has some overlapping. I just wanted to give you a quick heads up! Other then that, amazing blog!
SEO is not only about optimizing a website for search engines but also for the users. This improves the overall user experience and increases the likelihood of users returning to the website.
Hey are using WordPress for your blog platform? I’m new to the blog world but I’m trying to get started and set up my own. Do you require any html coding knowledge to make your own blog? Any help would be greatly appreciated!
magnificent post, very informative. I wonder why the other experts of this sector do not realize this.
You must proceed your writing. I am confident, you’ve
a huge readers’ base already!
https://illinoistechcon.com/
These are actually impressive ideas in regarding blogging.
You have touched some pleasant things here. Any way keep up wrinting.
https://hotelmariest.com/
Do you mind if I quote a few of your articles as
long as I provide credit and sources back to your blog?
My blog is in the exact same niche as yours and my visitors would definitely benefit from some of
the information you present here. Please
let me know if this alright with you. Cheers!
Your style is unique in comparison to other people I’ve read stuff from.
Thank you for posting when you have the opportunity,
Guess I will just bookmark this site.
If you are going for most excellent contents like myself, just pay a quick visit this web page all the time as it presents feature contents, thanks
Hello, i feel that i noticed you visited my site so i came to return the choose?.I’m trying to to find things to enhance my website!I suppose its adequate to use a few of your ideas!!
my website – https://Krishka.ru/proxy.php?link=https://www.trademama.com/candle-gift/usa/stores.html
I’m rеally enjoying the design and layout of your blog.
It’s a very easy on the eyes which makеѕ it much more
pleasant for me to come here and vіsit more often. Did you
hire out a developer to create your theme? Superb
ԝork!
my web blog Rafa88
Great site you have here.. Its hard to find high quality writing like yours these days. I honestly appreciate individuals like you! Take care!!
Also visit my webpage http://3Dhttps%3A//WWW.Trademama.com%2Fdressers-bedroom-furniture%2Fsuppliers.html/
Yeѕ! Finally someone rites about Rafa88.
Pretty! This was a really wonderful post. Thank you for providing this info.
Hello my friend! I want to say that this article is amazing, nice written and include almost all important infos. I’d like to peer extra posts like this .
Have you ever considered about adding a little bit more than just your articles? I mean, what you say is valuable and everything. But think of if you added some great photos or video clips to give your posts more, “pop”! Your content is excellent but with pics and video clips, this website could definitely be one of the greatest in its niche. Very good blog!
Highly descriptive article, I liked that a lot. Will there be a part 2?
Ӏf you would like to get much from this piece оff writing then you havе to
apply such stratewɡies to уouг won website.
Also viѕit my website: Rafa88
Nice ɑnswers in return of this matter with
genuine arguments and telling thhe whole thing about that.
my site … Rafa88
My brοther recommended Ι migһt like this web site. He used to bе totally right.
Tһis submit actuallү made my day. You can not imagine simply how
a ⅼot tіme I haɗ spent for this info! Thanks!
Take a look at my page – Rafaslot
I am rеgular visit᧐r, how are you everybody?
Ꭲhiis poist posted at this website is actually good.
my website; Rafa88
Savedd ass a fаvorite, I ⅼove yօur web site!
Here is my blog post … Rafa77
Ꮤhаt a material of un-ambiguity and preserveness оf precіous experience regarding unpredicted fеelings.
my pаge Rafa77
Іt’s actually a greɑt and useful piece of info. I am satisfіed that you shaгed this helpful informatіon with us.
Please қeep us informed like this. Tһanks for sharing.
My web blog: Rafa88
I actually felt this blog was relevant and timely, either) and living a life with appreciation for the randomness and
patterns of nature, keeps people feeling grounded. Considering vital memes is likewise some other sort of experience that can help us make the discovery of self understanding.
Tһis paragraph is really a good one it helps new tthe
web people, who are wishing for blogging.
Feel free to visit my web page: Rafa88
Great post. I was checking constantly this blog and I am impressed!
Extremely useful information particularly the closing phase 🙂 I care for uch information much.
I used to be looking for this certain information for a very long time.
Thanks and best of luck.
My homepage us Flags
Do you mind if I quote a couyple оf your posts
as long as I providе crerit and sources back to
your weblog? My bⅼog site is in the exact same niche as yours and my visitors would definitely
benefit from a ⅼot of the information you present here.
Ꮲlease let mme know if this okay ѡith you. Appreciate it!
Also visit my homepagе … Rafa88
Thіs piece of writіng offfers clear idea for the new users of blogging,
that іn fact how to Ԁo bloցging and site-Ƅuilding.
My web ssite :: Rafa88
Excellent pieces. Keep writing such kind of information on your page.
Im really impressed by your blog.
Hi there, You have done an incredible job.
I will definitely digg it and personally suggest to
my friends. I’m sure they will be benefited from this website.
Take a look at my site – six flags over georgia discounts
I’m not suure why but this website is loading very slow for me.
Is anyone else having this problem or is it a issue
on my end? I’ll check back later and see if
the problem still exists.
My site: world Flags
After I initially commented I seem to have clicked
on the -Notify me when new comments are added- checkbox
and now each time a comment is added I get 4 emails with thee sane
comment. Perhaps there is an easy method you are able to remove me
from that service? Cheers!
Here is my blog flag manufacturers
This is my first time pay a visit at here and i am truly happy to read everthing at alone place.
Havve a look at my website Six Flags Fiesta Texas
Fantastic goods from you, man. I have understand your stuff previous
to and you are just extremely excellent. I really like whjat you have
acquired here, certainly like what you are stating
and the way in which you say it. You make iit enjoyable and you still care for to keep it smart.
I can’t wait to read far more from you. This is actually a great webb site.
My webpage … Mariana
Hello there! I could have sworn I’ve been to this websute before but after browsing through
some of the post I realized it’s new to me. Anyhow, I’m definitely delighted I found it andd I’ll be bookmarking and checking
back often!
my web page: six flags over Texas coupons
I’m not that much of a online reader to bbe honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your website to come back later on. Cheers
Here is my blog post … six flags Magic mountain overview
Hello! I know this iss kind of off topic but I was wondering if you knew where I could find a captcha plugin for
my comment form? I’m using the same blog platform as yours and
I’m having trouble finding one? Thanks a lot!
Here is my blog – Internet marketing
I have a tendency to come across blogs along these lines at the most improbable moments.
For example at present, I had been seeking a specific
thing on an altogether different area and I found this website
instead. I all too often spend time scouting
the web for posts, but yet normally I prefer to be
out in the open, walking in the area woods. You’ll find nothing is
like fresh air to make you truly feel revitalized.
This can be as soon as i am not accomplishing work as
an at home massage therapist. It uses up a
lot of my own time.
Hi! Տommeone in my Ꮇyspace grօuρ ѕhared this site with us
so I came to loߋk it ovеr. I’m definitely lovimց the information.
I’m bookmrking and will be tweeting thіs to my followers!
Great blog and wonderful dеsіgn.
Look into my webpage Rafa77
What’s Tɑking ρlаce i’m new tߋ this, I stumbled upօn this I’ve discovered It ɑbsolutely
helpful annd it has helped me out loads.
I hope to give a contribution & aid οther uѕers like itѕ helped
me. Great job.
Here is my weЬpage; Rafa88
I thijnk the admin of this web page is genuinely working hard in support of his web page, because
here evedy information is quality based material.
my homepage –
Really wonderful visual appeal on this internet site, I’d value it 10.
My blog; https://Git.Avclick.ru/jqhmariana781/juan2002/wiki/Internet+Marketing+Tips+-+How+To+Paypal+From+Freezing+Your+Funds.-
Your article helped me a lot, is there any more related content? Thanks!
Good answer back in return of this query with firm arguments and describing the whole thing on the topic of that.
Here is my web-site … http://eng.komiss.org/bbs/link.html?code=schedule&number=97&url=https%3A%2F%2F40tag.com%2Flilianastr
I do not even know how I ended up here, but I thought this post was good.
I don’t know who you are but definitely you’re going to a famous blogger if you aren’t already 😉 Cheers!
I am not sure where you’re getting your info, but good topic. I needs to spend some time learning much more or understanding more. Thanks for great info I was looking for this information for my mission.
We are a gaggle of volunteers and starting a
new scheme in our community. Your web site offered us with useful information to work
on. You have performed an impressive process and our whole community can be
grateful to you.
My own daily life being a busy event massage planner does not leave
very much spare time over for contributing my own views on information articles, generally.
However, having already stopped in this morning, I was trying
to ensure I started out on the right footing, and get going with
a comment. It really is gladdening in my opinion that there is a blog post about
this vital issue, for the reason that it is not tackled nearly sufficiently in real life.
First, thank you for the info, and your completely unique perspective.
I could value this blogging site and specifically this informative article.
At this time, Personally I think I misuse far
too much time online, studying rubbish, generally.
This was a refreshing change from that experience.
However, I feel that examining other’s thoughts is a very vital investment
of at least a bit of my weekly measure of time in my schedule.
It’s the same as hunting through the junk heap to get the treasure.
Or, whatever example will work for you. Nonetheless, being near the
desktop computer is most likely as bad for you as cigarette smoking and fried potato
chips.
Glad to be one of several visitors on this amazing internet site :D.
Here is my web page … https://Www.artearqueohistoria.com/spip/spip.php?action=converser&redirect=https://Quickalert.net
Hello, Neat post. There is a problem along with your site in internet explorer, might test this? IE still is the marketplace leader and a big portion of people will omit your great writing because of this problem.
I will immediately grab your rss as I can’t in finding your email subscription link or newsletter service.
Do you’ve any? Please let me know so that I may subscribe.
Thanks.
Superb blog! Do you have any tips for aspiring writers? I’m hoping to start my own website soon but I’m a little lost on everything. Would you recommend starting with a free platform like WordPress or go for a paid option? There are so many choices out there that I’m completely overwhelmed .. Any recommendations? Cheers!
Woah! I’m really enjoying the template/theme of this website. It’s simple, yet effective. A lot of times it’s difficult to get that “perfect balance” between superb usability and visual appearance. I must say you have done a fantastic job with this. Additionally, the blog loads very fast for me on Chrome. Excellent Blog!
Hi! Do you know if they make any plugins to protect against hackers? I’m kinda paranoid about losing everything I’ve worked hard on. Any suggestions?
Here is my web page; https://Firsturl.de/hr8XW3P
Tһis post is actually a good one it ɑssists new the web νisitorѕ, who are wishing for blogging.
In acupuncture concept this is torpidity in the gallbladder network.
My site … acupuncture for sciatica – https://nohio.org/,
Wah, bahasan yang menarik banget nih! Dari apa yang saya lihat, situs yang modal kecil tapi gacor biasanya peluang menangnya juga cukup besar.
Kalau kamu lagi cari rekomendasi, coba cek daftar situs https://getgosmart.com 10k terpercaya. Mereka fiturnya lengkap dan gampang dimainkan.
Semoga info ini menambah referensi. Jangan lupa share juga pengalaman kamu kalau sudah coba ya!
I am not sure where you’re getting your info, but good topic. I needs to spend some time learning more or understanding more. Thanks for magnificent information I was looking for this info for my mission.
Very energetic blog, I enjoyed that a lot. Will there be a part 2?
They also present higher floor quality as a result of face layers can usually be laminated over base layers eliminating many or all of the fasteners within the face layer.
I’ve been surfing online more than 3 hours today, yet I never found any interesting article like yours. It is pretty worth enough for me. In my opinion, if all site owners and bloggers made good content as you did, the internet will be much more useful than ever before.
Beneath the Act, tenants can take legal motion in the event that they consider their rental home isn’t habitable – with damp and mould included on the record of 29 hazards inside the Housing Well being & Safety Rating System (HHSRS).
Aside from these there are Divorce attorneys, employment lawyers, fraud lawyers, medical malpractice legal professionals, software program legal professionals, site visitors lawyers, tax legal professionals, litigation attorneys and many others.
Awesome! Its actually amazing paragraph, I have got much
clear idea about from this piece of writing.
Hello, everything is going well here and ofcourse every one is sharing facts, that’s in fact good, keep up writing.
Ѕlot demo-nya gacor parah.
Auto index slot.
MultiChain
Slotnya cocok buat support.
Heya i am for the first time here. I came across this board and I find It really useful & it helped me out a lot. I hope to give something back and help others like you helped me.
Keren banget, langsung gue pake.
Auto index slot.
Link gue naik gara-gara ini.
Spam aman dan cuan.
Howdy! Quick question that’s totally off topic. Do you know how to make your site mobile friendly? My website looks weird when viewing from my iphone4. I’m trying to find a theme or plugin that might be able to correct this problem. If you have any recommendations, please share. Thanks!
I read this article fully regarding the difference of hottest and preceding technologies, it’s remarkable article.
I could not refrain from commenting. Exceptionally well written!
Thanks , I’ve just been searching for information about this subject for ages and yours is the greatest I have discovered so far. But, what concerning the bottom line? Are you positive concerning the source?
Nice post. I was checking continuously this blog and I am impressed! Extremely useful information particularly the last part 🙂 I care for such info a lot. I was looking for this certain info for a long time. Thank you and good luck.
Currently it seems like Expression Engine is the top blogging platform out there right now. (from what I’ve read) Is that what you are using on your blog?
I’m really impressed with your writing skills as well as with the layout on your blog. Is this a paid theme or did you modify it yourself? Either way keep up the excellent quality writing, it’s rare to see a nice blog like this one nowadays.
Ahaa, its nice discussion about this piece of writing here at this web site, I have read all that, so at this time me also commenting at this place.
Oh my goodness! Amazing article dude! Thank you so much, However I am experiencing troubles with your RSS. I don’t know why I cannot join it. Is there anyone else having similar RSS problems? Anyone that knows the answer will you kindly respond? Thanks!!
For the reason that the admin of this web page is working, no question very soon it will be well-known, due to its feature contents.
I really like your blog.. very nice colors & theme. Did you make this website yourself or did you hire someone to do it for you? Plz reply as I’m looking to design my own blog and would like to know where u got this from. cheers
Pretty nice post. I just stumbled upon your blog and wanted to say that I’ve really enjoyed browsing your blog posts. In any case I will be subscribing to your feed and I hope you write again very soon!
Hello There. I found your blog using msn. This is a very well written article. I will be sure to bookmark it and return to read more of your useful information. Thanks for the post. I’ll certainly return.
Very shortly this web site will be famous amid all blogging and site-building viewers, due to it’s good posts
It’s going to be finish of mine day, but before ending I am reading this fantastic paragraph to increase my know-how.
In Power Query, removing duplicates while keeping the last record (based on a specific sorting order, typically the latest or most recent entry) can be done efficiently.
I do not know if it’s just me or if everyone else encountering issues with your website. It appears like some of the written text within your posts are running off the screen. Can somebody else please provide feedback and let me know if this is happening to them too? This may be a issue with my internet browser because I’ve had this happen previously. Thanks
Appreciation to my father who shared with me on the topic of this web site, this weblog is in fact awesome.
Have you ever thought about including a little bit more than just your articles? I mean, what you say is important and everything. However just imagine if you added some great images or video clips to give your posts more, “pop”! Your content is excellent but with pics and videos, this website could undeniably be one of the best in its niche. Very good blog!
This piece of writing will help the internet users for setting up new web site or even a weblog from start to end.
Thankfulness to my father who stated to me regarding this website, this blog is actually amazing.
I was suggested this blog through my cousin. I’m no longer positive whether this put up is written by means of him as no one else know such certain about my trouble. You’re incredible! Thanks!
Thanks for the good writeup. It in truth was a enjoyment account it. Glance advanced to far brought agreeable from you! However, how could we keep up a correspondence?
Thanks for sharing your thoughts about %meta_keyword%. Regards
hello there and thank you for your information – I’ve certainly picked up anything new from right here. I did however expertise a few technical points using this website, as I experienced to reload the site lots of times previous to I could get it to load correctly. I had been wondering if your web hosting is OK? Not that I am complaining, but slow loading instances times will sometimes affect your placement in google and could damage your high quality score if advertising and marketing with Adwords. Anyway I’m adding this RSS to my e-mail and can look out for a lot more of your respective exciting content. Make sure you update this again soon.
Excellent write-up. I certainly appreciate this website. Thanks!
Hey I am so delighted I found your website, I really found you by accident, while I was browsing on Bing for
something else, Regardless I am here now and would just like to say many thanks for a marvelous post and
a all round exciting blog (I also love the theme/design), I don’t have time to go through
it all at the moment but I have saved it and also
added your RSS feeds, so when I have time I
will be back to read more, Please do keep up the great job.
This is my first time pay a quick visit at here and i am truly pleassant to read all at single place.
I all the time used to study paragraph in news papers
but now as I am a user of web so from now I am using net for articles, thanks
to web.
Thank you for such an excellent summary of this essay. I enjoyed the one before this one as well.
Excellent!!!
Hi, I keep rereading this because I feel like my answer is here somewhere but I can’t find it. I get a data set from an outside source. The data comes where the initial column is the keyID and there may be duplicates in the keyID; the last row in any duplicate set is always the row to keep (independent of ascending or descending sort of keyID column. There is no data with any time or date attributes so there is no ability to sort within duplicates except I know the last row is always the most current status. So effectively, I want to “Remove Duplicates” and keep last row instead of first. Any thoughts?
Your above analysis is very helpful for other data sets I get which have sortable data elements.
You could manually add an index column to the raw data inside PQ. this would give you the sort order you need. The rest of my blog should then work
Great solution!! It works perfectly!!!
Thank you so much ♥
HI all, great solution, thanks for spreading.
Am I the only one struggling with the performance? I’m trying in a dataset with 1 million rows more or less and I receive this error: evaluation ran out of memory and can’t continue.
Any suggestion?
Yes, it’s going to be inefficient. PQ is not a DB. If you can solve this problem elsewhere (Ie in the source if it’s a DB), then that is better.
Thanks for replying!
Do you think the buffering+remove duplicates will work if the source is a DB (in my case is not, the source are .csv files in a sharepoint folder) or do you think the entire action should be done in the DB directly?
If the source is a DB, it will depend if the PQ Query can query fold back to the DB. My guess is no, but I can’t be sure. If the source is a DB, then I suggest getting a DBA to write a query that removes duplicates and use that as a view.
Great solution thx – once i do this performance slows down and it takes a long time to run the query. I have over one million lines of data to process so appreciate it takes time to run, but now its even longer, are there any tips on how to speed this up please
This will never be fast. This Query needs to load all data I to memory first. If there’s not enough memory, it will page it to disk while loading. To make it faster, you would need to load it into a database and process it there. Depending on the data, you may be able to pre-process the 1m records and write to a “history” csv. Then incrementally load the new data and only remove duplicates from the new data. The may or may not work depending on the data
I adore both the explanation of the problem and the easiness of the solution. Thx!
Simple yet a brilliant idea ….. your are genius !!!
Thanks it helped me 🙂
The solution is simple and works perfectly!
Bro, you are a genius. Thanks for such an easy to understand explanation.
Brilliant solution been wracking my brain for ages thank you
Thank you! This was very helpful and it works.
Thanks so much, I didnt need to go via “group by” afterall, as this works really well. thanks
THANK YOU!! This has made my day!
Thank you very much Matt Allington. This awesome solution and very clear explanation has hugely helped me tonight … great great relief.
Thanks a lot for the insight and method!
I am worried that this will severely impact the performance of Power Query as I am filtering 1-2 Million Rows of Data.
Has anybody tried this a bigger amount of Data?
It absolutely may be an issue. If it is, you should move to a DB in the back end.
Brilliant! Really appreciate the explanation and the solution 🙂
Matt Allington,
I applied the table.buffer in my model, but I noticed that for small databases, the solution works well. But when applied to bigdata, especially when applied to dataflow within the power bi portal, I noticed a huge decrease in the application’s performance, even crashing the system. Do we have another solution?
Yes, the solution is to do it in the source database.
It worked for me today. Thanks a ton Matt for this wonderful article.
This does not work
Make sure you are using the Table.Buffer function around your Table.Sort, otherwise the Lazy Evaluation steps in and will chose to ignore the Sorting step.
Same, did not work. Went through options and cleared my cache, restarted Power BI desktop.
Mmm, I don’t know why, but I think the DAX/image above is wrong. I believe the table.buffer should be inside the sort function. If you think about it, we need to buffer the table first, then sort it. Please try that and let me know.
I just did a quick crosscheck, and confirm that the technique works.

The correct M is
Table.Buffer(Table.Sort(#”Changed Type”,{{“OrderDate”, Order.Descending}}))
Thanks Matt, that was awesome!! Everything works fine just one issue – I have duplicates in Order Date.
Following the above steps give me the correct output for some and incorrect for other. By incorrect I mean – I get the 2nd last record from the Order Date and not the last one. No clue why, can you please advise?
Thanks in advance.
It’s hard to say. You could use groupby instead. Do a groupby on the columns you have and then max on order date
Thanks Matt! You helped me today
This helped me today. Thanks, Matt!
Thank you so much. Very useful and educational!
Thank you a lot!!!!! It really works!!!!!!!
Great Post – Well explained!
I’ve been having issues with this for a while, now added to my bookmarks!
Thank you Matt, learned a neat new trick today!
Hello,
And If I need to remove duplicates only per month? For instance, I have the same entry twice in November and Once in October, but I need to remove only the duplicated from November and Keep One for November and the on from October?
Thanks in Advanced.
I suggest you try to “Group By” month, and then aggregate on the item you need. I guess there is a “first” option. You would have to check.
Thank you so so much for this.
Hey guys, I would like to say thank you from Brazil. I was suffering to solve this issue. Congratulations for the work here!
This is awesome! It solves a longstanding problem I had with duplicate client entries in table with different discharge dates. I am working with complex patient treatment data, and I need to have unduplicated lookup table for client discharge reasons. Thank-you!!!!
I was just wondering about this myself! I thought there muse be some wrong here and indeed there is.
I did some experiments with a smaller data set. I found that for those 2 activities, remove duplicates and sort, the the first appearance of a duplicate row before being sorted is always kept. My guess is that When PQ meets those two activities, it always executes remove duplicate first, therefore the first appearance is always kept. Hope you know what I am saying.
Hi Jordan,
That’s because of the “Lazy Evaluation”.
That’s why we need to use Table.Buffer() to force Power Query to load and sort the entire data set before removing duplicates.
This is exactly what I need this morning! Thank you!
Thanks. Saved my day. Stuff like this is hard to even know it’s not working right when you’re dealing with 1000’s or records. Only when things have gone too far wrong or it’s too late, we’ll know we need to investigate only to find out that the software decided to be “lazy”.
Thank you so much Sir! Your post solved my problem in a flash!!!
The request seems very simple, but I can’t solve it until reading this page. Thank you.
Thank you so much for this!
Hi, I need to find a way to delete not only one of duplicated records but to delete all records which appear to be doubled. We are using this option to review all employees internal movements from NH and termination list. Removing duplicates is always leaving one record behind when i don’t need any of it. When employee moved internally should not be on NH list nor on Termination list. In regular excel file i just mark them with color and delete manually but I want to create query and i can’t seem to find a way to do it automatically. Help please 🙂
Well, the short answer is this. What is the repeatable process you use to manually identify the records you don’t need? You need to be able to extract the logic from that manual process so you can write a query to do it for you. Of course, it depends on the situation, but that is what you need to do.
Group by employee name, accepting the default parameters, then filter Count to 1.
This has solved a problem for me in seconds that I had been struggling with for days, Many thanks for the solution and explanation of what causes the issue in the first place
Thanks a lot for this article! It really helped quickly solve the issue i was facing.
It worked. OMG. How to know what we don’t know? Thanks anyway!
The above solution has really worked with the query of similar type with my report. Thanks
I was fortunate enough to find this guide before implementing the solution and possibly getting incorrect results. It boggles my mind that Power Query would work in this “lazy evaluation” mode without some more or less explicit warning about this functionality. I wonder about other cases this can generate possible issues. Maybe anyone has some further insight? Thank you for the article!
The solution works perfectly. The use of Table.Buffer saved my day!
Thank you so much.
Perfect! I was tearing my hair out trying to figure this out. I knew it must have to do with query folding, but didn’t know a way around it. Such a simple and elegant solution! Thanks!
BRILLANT! Thank you!!!! 1000 times
Thank you so much for this article. This is the exact method o need to apply to my data set to obtain the unique results.
Thanks! It was driving me crazy. The solution you suggested works perfect!
This was really helpful. Thank you
It depends what you are trying to do when you say “processing” and “a long time”. Refresh typically takes 2 – 30 mins depending on column and complexity of transformation. Power BI is a reporting tool that has its own ETL. If the source is not a database, then ETL can be slow.
Hi,
I have about 1 million records of data in csv file and need to process them and create the reports.
Is powerbi suitable for this mean?
when i load data in powerbi and use power query for processing , this takes long time.
Oh this page is really helpful. You saved me from a disaster. Thank you so much.
Thank you Matt. This worked perfect.
This was very helpfull ! thank you so much for helping 😉
Saved my report! Thanks!
Excellent! Thanks Alot
This has not worked for me using google sheets as a source.
Genius thank you!
Thanks a million Matt! I have a few suppliers sending me their stock on hand reports regularly via Excel. I have been consolidating them into one sheet. To get the latest stock on hand by each supplier, I could use max/maxx measures for visuals/reports in Power BI. But what I really wanted was for Power BI to only load the latest stock on hand data by each supplier. Your solution was exactly what I wanted in the first place. If this post had a title like “only load/filter/keep the latest/last record by customer/product/supplier via Power Query”, I’d have found it much sooner… LOL. Cheers Sean
Thanks so much for this info…. I was wondering how could the sorting/duplicatesRemoval not work properly..
This post showed me the full picture about the “partial sort”…..
Really Great.
Regards
//Lünkes
Amazing! I’ve spent so much time fighting with deduplication issues. This has brought my skills up another notch!
This was really great. Thanks for the good explanation .
You are amazing, no one had this answer in spanish, thank you so much!
I had this exact problem and you just saved me hours and hours of frustration. Thank you!
Thank you so much for this article…this has been a problem for me for some time…problem solved…I was removing duplicates manually because I was not getting the expected results…You have saved me so much time going forward. Very much appreciated!!!
Best case for Table. Buffer. Thank you so much.
I thought I had the problem solved, until I recently performed an audit and discovered otherwise. Wrapping the Table.Sort function in the Table.Buffer function worked like a charm! Can’t thank you enough! 🙂
Thank You so much, Mr. Matt Allington First sorted data in descending order then applied to remove duplicate so removed old record data instead of a new one as per modified date. So once again thank you so much.
Thank you so much! This article is so helpful to me. I have been working so hard months and this solution helps me to finish my work.
This is an excellent solution.
Thanks
Thank you very much!!! Brilliant your explanation it saved my life. Good to know that even the computer is lazy sometimes.
Matt,
Colin Bandfield from Msft came to the rescue some time ago with a very elegant solution:
https://social.technet.microsoft.com/Forums/en-US/0cc2a3fe-38ec-4e0b-9dcc-abb9b5cd9f9b/group-data-and-sort-rows-inside-group?forum=powerquery
regards,
I’ve also found that adding an index column between the sort and remove duplicates steps also produces the correct result.
You are the best
Hi Matt,
Thank you for this article and for this trick.
In this example, if we have more than 1 article bought in the same date, I think it’s better to use the “Group By” method.
Hoss
Hi Matt,
If Table.Distinct finds more than one row with duplicate values in the specified column list (which just contains column CustomerKey, in this case — Table.Distinct(#”Sorted Rows”, {“CustomerKey”})), I believe it’s free to return any one of those duplicate rows, at its convenience (documentation [https://docs.microsoft.com/en-us/powerquery-m/table-distinct] doesn’t promise that it will return the first or last row out of a sorted set of duplicates). This makes me think that the non-working solution is really working correctly–just not producing the desired output.
If Table.Distinct happens to respect sort order in some circumstances (like when working with a buffered input), it seems like this would be an internal implementation detail that could change and might not hold true across all platforms (PBI, ADF, etc.).
Ben
Yes, I wasn’t trying to imply it wasn’t working correctly – just that it doesn’t do what you may expect
Nice trick. One that I have used often especially with big data. What’s the hit to performance however?
Fair question, but not as Important as getting the correct answer. I suspect performance will be fine except for large data. The data has to be loaded anyway. Even if you use groupby, PQ still has to load all the data before proceeding.
Hi Matt,
Great post, thanks for sharing.
I added Conditional Formatting in the Sales_IncorrectSolution.
1 Added Column: RelCorrectDate = RELATED(Sales_CorrectSolution[OrderDate])
1 Added Column:EqualYesNo = IF(RELATED(Sales_CorrectSolution[OrderDate])=Sales_IncorrectSolution[OrderDate];1;0)
Conditional Formatting based on the column EqualYesNo
Greetings
Nice work Matt, I was working on a DiFOT report just yesterday and did the same thing you mentioned; sort by then remove duplicates. Then your email came out last night, talk about timing. Thank you.
Matt, I add an INDEX column after the sort step. Fixes the issue. Think I read that on Reza’s blog once upon a time
Like you say, a number of ways to address this. Maybe a sort should automatically trigger an index step? Things like Promote Headers triggers an automatic change type step.
Hi Matt,
Although there are multiple ways to resolve any problems, thanks for sharing this with an example, I learnt new and unique command(Table.Buffer()) today, which will be more helpful when I working in power query,
Thanks for sharing this – it’s useful to learn the quirks and potential solutions. You never know when that information might come in handy.
Sweet solution. I was not aware of Table.Buffer().
side note: There is a phrase between brackets before the last table that is not supposed to be there 🙂
regards
Thanks x 2 🙂
That’s it. That is the point of this post
I’m thinking that you should just reference the original table, group by customer key and do a max on the date field, and then use this result to inner join back to the original table on customer key and date. Seems like a straight forward solution. It probably pushes down to the database too. And no need to hack code?
Thanks,
Scott
Yes, that is a valid solution. However I like to share what I learn about these tools to expand readers understanding and capabilities.
Try this trick 🙂 … Insert “stupid step” between Table.Sort and Table.Distinct… e.g. you can change type OrderDate on the type datetime
It “freezing” table in sorted state…. and after that you can remove duplicates properly.
Polish/English version :
…
#”Posortowano wiersze” = Table.Sort(#”Zmieniono typ”,{{“OrderDate”, Order.Descending}}),
#”Zmieniono typ1″ = Table.TransformColumnTypes(#”Posortowano wiersze”,{{“OrderDate”, type datetime}}),
#”Usunięto duplikaty” = Table.Distinct(#”Zmieniono typ1″, {“CustomerKey”})
…
Maybe I’m not understanding the full extent of the problem but I found simply grouping on CustomerKey and taking the Max of OrderDate produced the same result.
let
Source = Excel.Workbook(File.Contents(“C:\Projects\Consulting\PowerBI\Removing-Duplicates-Sample\5 Tables in Excel.xlsx”), null, true),
Sales_Sheet = Source{[Item=”Sales”,Kind=”Sheet”]}[Data],
#”Promoted Headers” = Table.PromoteHeaders(Sales_Sheet, [PromoteAllScalars=true]),
#”Changed Type” = Table.TransformColumnTypes(#”Promoted Headers”,{{“ProductKey”, Int64.Type}, {“OrderDate”, type date}, {“CustomerKey”, Int64.Type}, {“SalesTerritoryKey”, Int64.Type}, {“SalesOrderNumber”, type text}, {“SalesOrderLineNumber”, Int64.Type}, {“OrderQuantity”, Int64.Type}, {“UnitPrice”, type number}, {“ExtendedAmount”, type number}, {“TotalProductCost”, type number}, {“TaxAmt”, type number}, {“Freight”, type number}, {“RegionMonthID”, type text}}),
#”Grouped Rows” = Table.Group(#”Changed Type”, {“CustomerKey”}, {{“Last Order Date”, each List.Max([OrderDate]), type date}})
in
#”Grouped Rows”
Yes, that will also work. But remember this is a simplified example to demonstrate the technique. What I didn’t say in the post was that in reality the customer need was a bit different and she wanted to keep the entire record with 15 columns. This can still be done with group by but is harder.