I was doing some work for a customer this week – they had a performance issue with a Power BI report. The data in the workbook wasn’t overly large, about 400,000 rows, yet the file size was 110 megabytes and the performance of the model was relatively slow given the number of records. When I looked at the report I noted that the report was using GUIDs between the primary and foreign keys on a number of tables. Generally speaking, it is not good practice to use a GUID to join tables, as GUIDs do not compress well and have a negative effect on the efficiency of physical 1 to many relationships.
What is a GUID?
GUID is an acronym for Globally Unique IDentifier. In short a GUID is a hexadecimal number that is the equivalent of a decimal number with 39 digits – something like this 1,000,000,000,000,000,000,000,000,000,000,000,000,000 (a Duodecillion). Stated differently, a GUID is a highly unique ID that is unlikely (based on probability) to be reproduced even if it were generated randomly – which they are. Read more about it here:
https://betterexplained.com/articles/the-quick-guide-to-guids/
What is Wrong with Using GUIDs in Relationships?
A physical 1 to many relationship in Power BI is a fundamental part of the underlying database structure. The Power BI engine (Vertipaq) materialises and stores these relationships into the database and then uses them to rapidly propagate filters from one table to another (via the 1 to many relationship). It is very common (even desirable) that the relationship logic is loaded in to fast L1 or L2 cache memory on your PC chip so that it can do its job super fast. If the relationship doesn’t fit in cache memory, then the whole process is going to be slower. Things that can drive up the size of the relationship are the number of unique values in the columns used in the relationship, but also the data type used in the relationship. Suffice to say, a GUID is way way less efficient that an integer value as a key column in Power BI.
Enter a Surrogate Key
One way to solve this problem is to replace the GUID with a surrogate key. A surrogate key, as its name suggests, is a new “key column” that is a “surrogate” (or a replacement) for the original key column. In a perfect world where you have SQL server at the back end, and you have an IT department that can do the work for you, I would suggest you get your IT department to build the surrogate key for you and make it available in a view so that you don’t have to use the GUID. But the world we live in is not perfect hence this article will show you how to replace the GUID with a surrogate key using Power Query.
Steps to Complete
Assuming you can’t get the work done at the data source, this is essentially a problem for Power Query to Solve. The steps to complete this process are as follows
- create a connection to the raw dimension table
- create a branch in power query
- add a new integer ID column (surrogate key)
- re-join the surrogate key table back with the original dimension table and replace the GUID using merge
- repeat the step to replace the GUID in the fact table
This process assumes that your dimension table contains a complete list of keys that exist in your fact table . If this is not the case, you have a problem anyway. It is possible to vary this pattern to include the GUIDs coming from the fact table too, however it actually doesn’t solve the root problem (that you may have IDs in the fact table that are missing in the dimension table) hence I have not provided/suggested this as part of the solution. Besides, doing this will certainly slow the refresh time without solving the root issue.
Connect to the Data
As you can see in the image below, I have two queries (RawCustomer, RawSales shown as #1 below) that connect directly to my sample data (I have modified Adventure Works so that the Customer number uses a GUID #2 below). Note my two Raw Data queries are simple connections. This is the technique Ken teaches in the Power Query Academy training, and I think it is a great practice. From there I created two staging queries (shown as #3 below) that are simple references to the raw data queries

So at this point, it simply looks like this

Create a Branch in Power Query on the Dimension Table
- The next step I followed was to right click on the customer staging query and select “reference” to create a new branch. I called this new query CustomerGUIDs. In this query I simply kept the GUID column and removed everything else. As a safety step I remove duplicates just in case there was a duplicate in the GUID column (even though it is unlikely).
- I then added an index column starting at 1, and called it CustomerID.
The new CustomerID column is the surrogate key. The beauty of this approach is that the surrogate keys will grow over time if the original GUID list grows (which is highly likely). Also, if there are any deletions from the customer table, the surrogate key will just rebuild itself to the new set of data.

Re-join the Table of Surrogate Keys to Form a new Dimension Table
-
Next I took a second branch from the customer staging query (right click “reference”) and merged it with the CustomerGUIDs table.

- Then I extracted the surrogate key
- Then I deleted the original GUID from the final customer table.
You can see the before (#1) and after (#2) version of the Customer table below.

Repeat the Process to Replace the GUID in the Fact Table
- I created a new query from the SalesStaging query (right click, “reference”) and merged it with the CustomerGUIDs table.
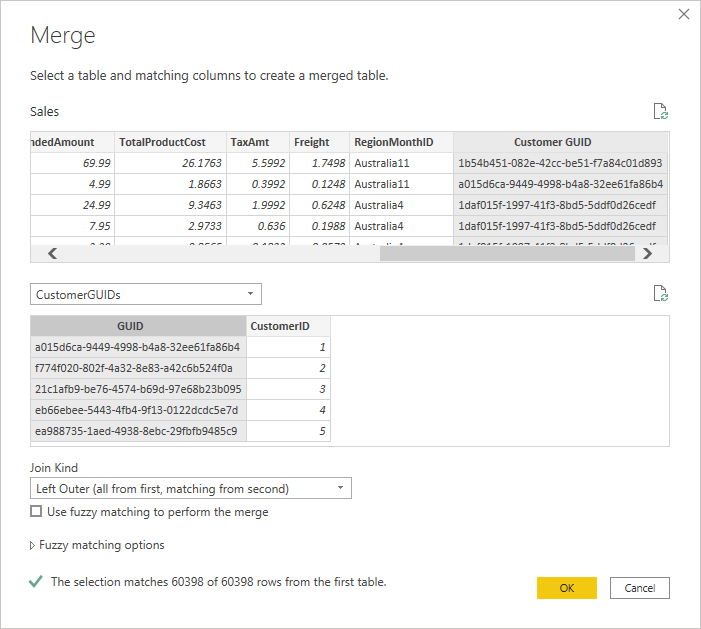
- Then I extracted the surrogate key
- Then I deleted the original GUID from the final sales table.
My final query dependency view looks like this.

I made sure all tables were set so they did not load apart from the Customers and Sales tables.
Results
The demo I have showed you here is with a very small dataset (19,000 rows). In my case the surrogate key approach reduced the file size by more than 30%, and there was only 1 table of surrogate keys in my file. In the case of my customer that had around 400,000 rows of data, 3 GUID key columns and a much higher number of unique GUIDs, the file size reduction was much greater, from 110MB to just 11MB (90% reduction with the surrogate key). Probably more importantly there were noticeable performance improvements after the cahnge.
Are There Any Negative Impacts?
Refresh Time
At this point you might be asking yourself “won’t this slow down the refresh time?”. If you were thinking this, you are absolutely correct, it will most likely slow the refresh performance. However, it is much better to have a slower refresh time and a faster runtime performance than the other way around.
What if I need my GUIDs for Auditing?
A second issue is that you may need the GUIDs so you can trace the data in your report back to the transaction in the source system. If this is a common need with your data, then I suggest you still create and use the surrogate key, but also load the GUID in the dimension table as an additional column. That way, the GUID is available but not used in the relationship. Better still, remove the GUID from the dimension table and then bring it back later only if you have an issue that needs you to trace the source.
Wrap Up, and Where to Learn More
Here is a copy of the workbooks I used in this article in case you are interested in taking a closer look.
If you would like to learn how to be great using Power Query, I recommend you take a look at the Power Query Academy online training at Skillwave.training. Ken, Miguel and I have teamed up forces to create the best, most comprehensive Power Query training course available.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article. http://gate-io-xtz.cryptostarthome.com
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Thanks for nice article, I am facing a similar situation where I need to create surrogate keys and would like to get rid of guid’s for relationships. But I have a doubt about the proposed solution. If a new customer is added to the data, wouldn’t that potentially break the indexing that appears to be tied to the sort order of the guids? I.E. potentially shift all the index keys and royally mess up the data model?
I am guessing this method always requires a full refresh of the source data, and wouldn’t work with incremental loads of fact tables. Or am I missing something here?
It does require a full refresh of the dimension and fact table. A new customer will change the integer index, but that’s not a problem as long as you do a full refresh. It won’t work for incremental refresh.
Hi Matt,
we replace GUIDs with an index (Surrogate Keys) in Power BI for all dimensions and fact tables i Power Query.
In Power BI desktop everything works perfect BUT after publishing into Power BI Service it does not. All facts rows do not have any relation to any dimension row (Custommer, Cost center …), they are reported as “blank value”. Have you ever had similar problem please? Dou you have any advice please?
Thank you
No, I have never heard of this. If it works on desktop and not on the service, I suggest you report it as a bug to MS for investigation.
Hi Matt
Thanks for a great post.
I am wondering why you create the extra layer with CustomerGUID?
Could you not more simply:
1. Create index column on Customers
2. Merge Customers and Sales on GUID and expand index column
3. Delete GUID columns in both tables
Thanks
You are right – I don’t know what I was thinking.
🙂
Of course if the data model is created without CustomerGUID as a middle layer it is not possible to delete the GUID column in the Customer Dimension.
Due to this I have actually begun creating this middle layer CustomerGUID, in order to replace and remove the GUID columns on both the fact and dimension tables.
Hi Matt,
How did you get your GUID to appear in that format (8-4-4-12)?
When I extract that column it appears Binary, I would love to know how I can convert that to the above mentioned format?
Regards
Randy
I did not format my GUIDs. This is the format they are in the database.
Matt,
Thanks for this information. It bears directly on an issue we are having with out data warehouse on Snowflake and Power BI.
We are facing an issue with truncation of numeric surrogate keys in Power BI when connected to Snowflake and were ironically discussing converting to GUIDs to address the problem.
We currently generate Surrogate IDs on Snowflake for all tables. Snowflake stores both decimal and integer values as numbers, so our Integer IDs are represented as Number(19,0). Power BI interprets this as a decimal, which is only supported to 15 digits, so an ID of -9223191239154221888 is stored in Power BI as -9223191239154222000.
When users are building Power BI data models with only imported data, we are not seeing collisions on the IDs (yet). Direct Query data models are also not affected.
However, with composite models, we are seeing issues where the imported ID, which is truncated, does not match up with the ID on the database when passed as a filter in a direct query.
We prefer not to require our uses to duplicate and transform columns to address this, so were considering transforming our surrogate key approach to use GUIDs instead to avoid the truncation of the key. Another option is to create a “text” version of the surrogate key, so that -9223191239154221888 is stored as a text vs a number. However, it seems like this would face similar issues with memory as a GUID?
I would expect a text based version of your SK would have similar impacts as GUIDs. The best approach is to create new SKs that are small integers if possible. Best to do that in your DB if possible.
Great post, I have implemented this on one of my models looking at Dynamics CRM Data, where I am connecting all my tables on GUIDs. I have not noticed the compression levels you have experienced in your example, my change in model size was only ~300kb per GUID column, (changed 2 columns with this method and got a 600Kb reduction) and that is with a fact table of 4.5M rows. Saying that, the query time improvements have been noticeable, with my queries running 50% quicker. I am going to play with this method in more depth to see what can be achieved with it on the compression side. Thanks again for this Matt.
Great. Did you remove the GUIDs after creating the surrogate keys? That is where most of the size benefit will come from.
Absolutely, I am going to run through some more tests to see what is achievable ( I have many many reports I can test this on! ) Will definitely post back with any findings.
Thanks for the detailed post Mark. My questions-
1. As we are bringing in a non foldable operation of index creation, I guess this impact the refresh.
No?
2. Also, in case of incremental refresh of the fact, for any deletion in dim- if the surrogate key rebuilds itself, will it not break the dim- fact relationship ?
Yes, refresh will be negatively impacted. Regarding incremental refresh, use extreme caution. I’m not sure I would do it.
Clear and practical post as usual! As a best practice, the creation of index/surrogate key should be pushed upstream into a data warehouse if possible, to reduce the refresh time in PowerBI workflow. If DW is not available, then try to push this operation into PBI dataflows to offload the data refresh time.
Correct, however be aware that dataflows will not work with referenced queries unless you have premium. You can do the reallocation of the surrogate key in the dim table without the need for referencing another query, but you can’t then do the same thing in the fact table. So dataflows is only an option if you have premium.
I guess as a best practice that you would want any new customers that are added to the customer dim to be added at the end of the table so that the existing CustomerIDs would not shift and change their sequence which could cause an issue if you are referencing CustomerID in a DAX expression and also for consistency? Or how else would you suggest keeping the customerIDs consistent when new customers are added to the customer dim?
These surrogate IDs will change, as you have suggested. A GUID is randomly generated so it is not practical to append them to the end of a list. If there were a requirement to refer to a unique ID in a measure (hard code), then I guess I would simply keep the GUID in the dimension table too. The dim table is the most efficient place to keep the GUID, as long as it is not part of the relationship
Insightful, Matt! I particularly like the trade-off of Faster RunTime to Refresh time if, for example you don’t want to jeopardize Self-service Reporting on PowerBI.
If you have to leave GUIDs in any table for reference, you can split them into multiple columns which should reduce the unique count in the table and speed up performance as well (like splitting up datetime to date and time)
Very good point, Gregory!
Good stuff! Been doing this since my early integration of crm with pbi in 2018. General rule I have is that if the dataset is greater than 10mm rows then ssas gets grumpy (depending on capacity sure) and it’s time to start trimming off long text, and basically any long type field that the engine will struggle compressing off the main tables.
“Things that can drive up the size of the relationship are the number of unique values in the columns used in the relationship, but also the data type used in the relationship”
So is this effect because it is a GUID (stored as text) or because the GUID is 39 characters long? I am just wondering if there is any significant difference between using an ID of 15 digits versus an ID of 18 digits? And how does a 15 digit number compare to a 15 digit text field as an ID?
Very good questions. Actually, a GUID is 36 chars long, made up of Hexadecimal numbers and 4 separators. The cause of the inefficiency is both – data type (text) and length (36 chars). Yes, there would be a difference between a 15 and 18 char id, but I couldn’t say how much difference. It would depends on the number of unique values. If you are going to go to the trouble of creating a surrogate key, then a whole number is the most efficient (I believe).
Would be great to get some proper prove on the performance savings achieved by integer keys. Well, it sounds reasonable to use them as they are crucial i.e. in SQL joins, but I already did several tests on that and couldn`t confirm the speed improvement at all. The best example I could bring here is my biggest SSAS model, where 200M rows of transactional data are connected to the customer table with 1M unique entries using text key “SOrg/Sold-to/Ship-to” and still works perfectly. I suspect that vertipaq engine anyway creates his own vocabulary keys to ensure good performance for users with less technical knowledge behind.
Wherever I decided to put integer key anyway, my approach is to produce index key for dimension table in Power Query, but not for Fact table as it can influence refresh performance really badly especially for big tables. Instead, I am adding it to fact table already in the model, using LOOKUPVALUE in DAX calculated column. Again we can argue on table compression, sorting etc., but I found it most convenient both for me and my users!
In the world of Tabular, I say “do what ever works for you”. If you don’t have a problem, then there is nothing you need to do. You are only likely to see material performance improvements when the change in relationship sizes triggers a change in the way relationships are handled in memory, particularly the usage of L1 and L2 Cache.
There is indeed encoding done by Vertipaq called Dictionary Encoding. It translates all datatypes to integers. Even large integers can be encoded into smaller integers. Dictionary encoding is only performed when it actually results into a smaller datasize. If dictionary encoding leads to a higher datasize then Vertipaq doesn’t apply it. GUID’s are very long so they will always be dictionary encoded. The relationship, that is psychically stored, uses this created integer and not the original datatype. The process Matt explained shouldn’t make a difference in relationshipsize and should on this front not make a difference on performance. What does matter is the Dictionary Size. This dictionary would be a lot bigger when there are a lot of GUID’s that need to be encoded.
(you can check this with VertipaqAnalyzer) If these primary keys would already be integers there would be no need for dictionary encoding and thus no dictionary size at all. The datamodel would therefor be smaller in datasize and so would consume less memory. Therefor Matt’s approach would be very usefull. However, performancewise I myself also haven’t seen significant (perhaps just a little) performance improvement when replacing string keys with surrogate keys..
As somebody analysing a lot of Dynamics CRM data, this post has proved invaluable. The compression of guids was not even something I had considered! Cheers Matt.
I hadn’t thought about Dynamics, but of course, this would be a great tip for any Dynamics reporting.