In a recent post, Matt discussed how to extract data from complex websites with Power BI using the New Web Table Inference capability of Power Query. This article is an extension of those ideas, revealing that this amazing feature is not just limited to scraping data from static HTML websites, but can also be used to scrape data from dynamic websites that reveal tabulated data through a JavaScript instance. There are currently some limitations however, so read on to learn more.
Extracting Website Data
As discussed in the previous article, prior to the development of the New Web Table Inference feature in Power BI, extracting tabular data from websites only worked well when the page had an underlying HTML table presenting the data. But with the new Web Table Inference feature in your toolbox, Power Query analyses the underlying code in the rendered page of the target website to work out what data to extract. At the time of this writing, the New Web Table Inference feature is still being developed and hence doesn’t work for all web pages, and sometimes needs a little massaging, but the potential of this feature is very exciting.
To activate this feature, go to File\Options and Settings\Options\Preview Features and turn on New Web Table Inference.
Scraping Dynamic Data
Let me show you how to use this new feature to extract data from a JavaScript instance within a JavaScript page on a website.
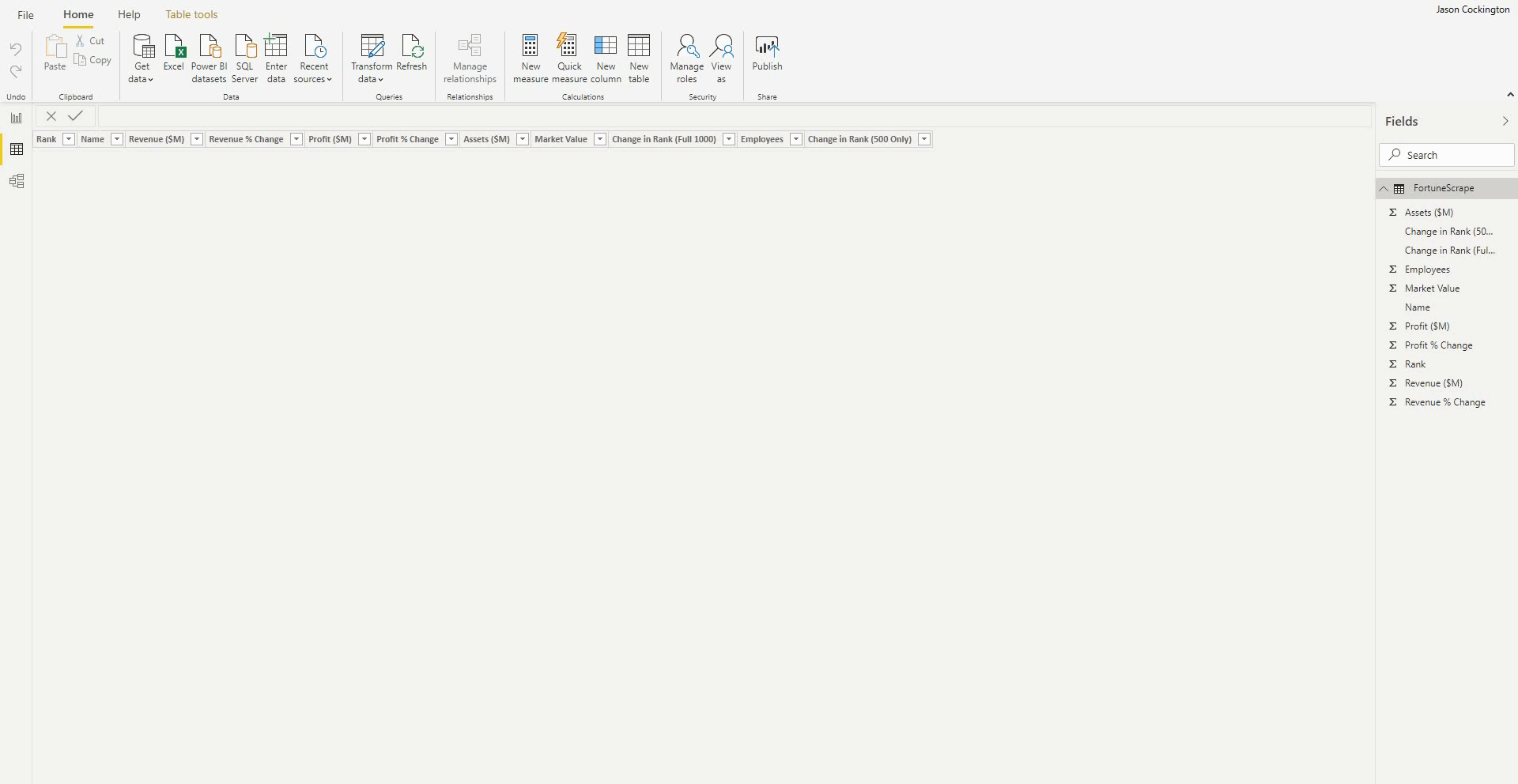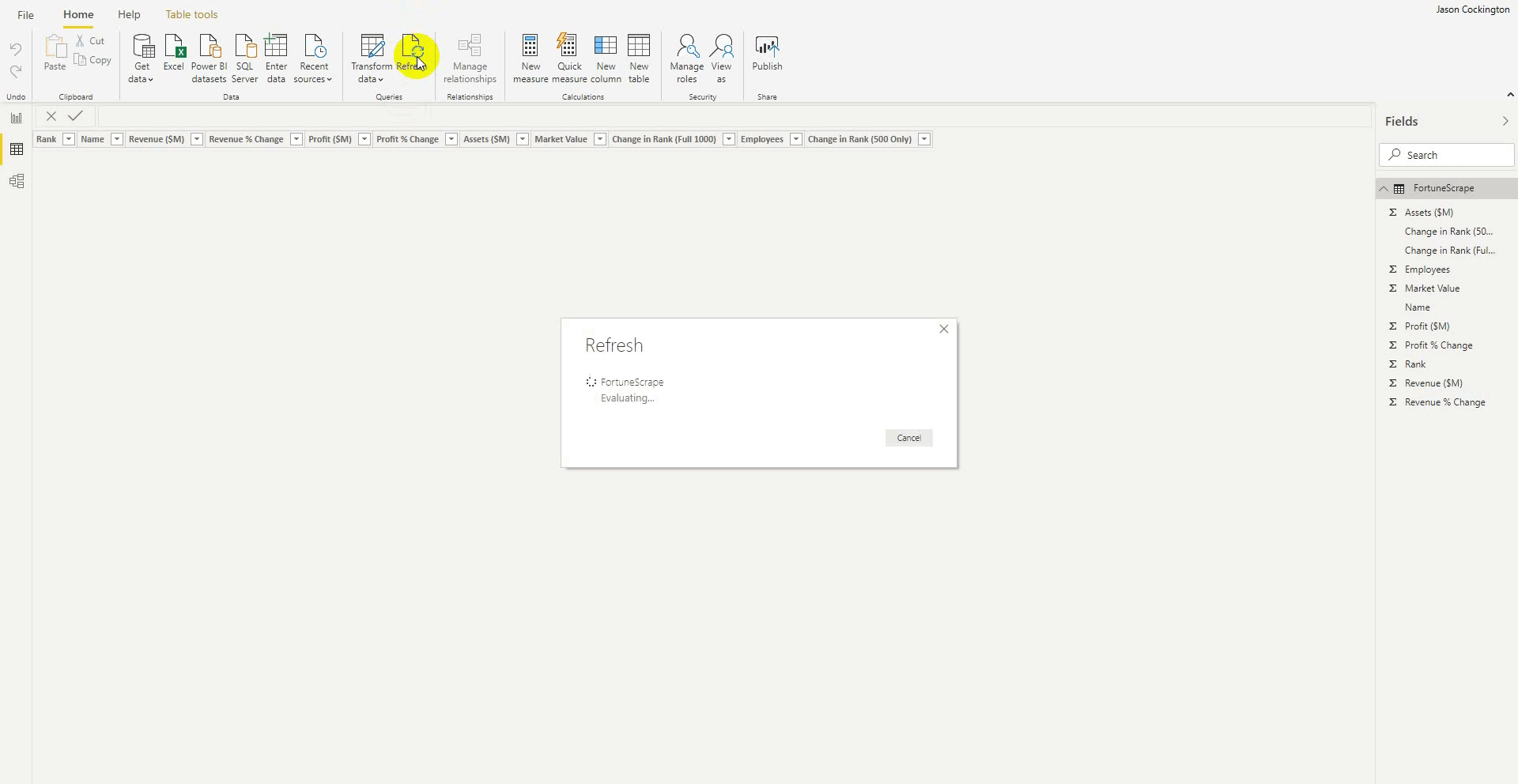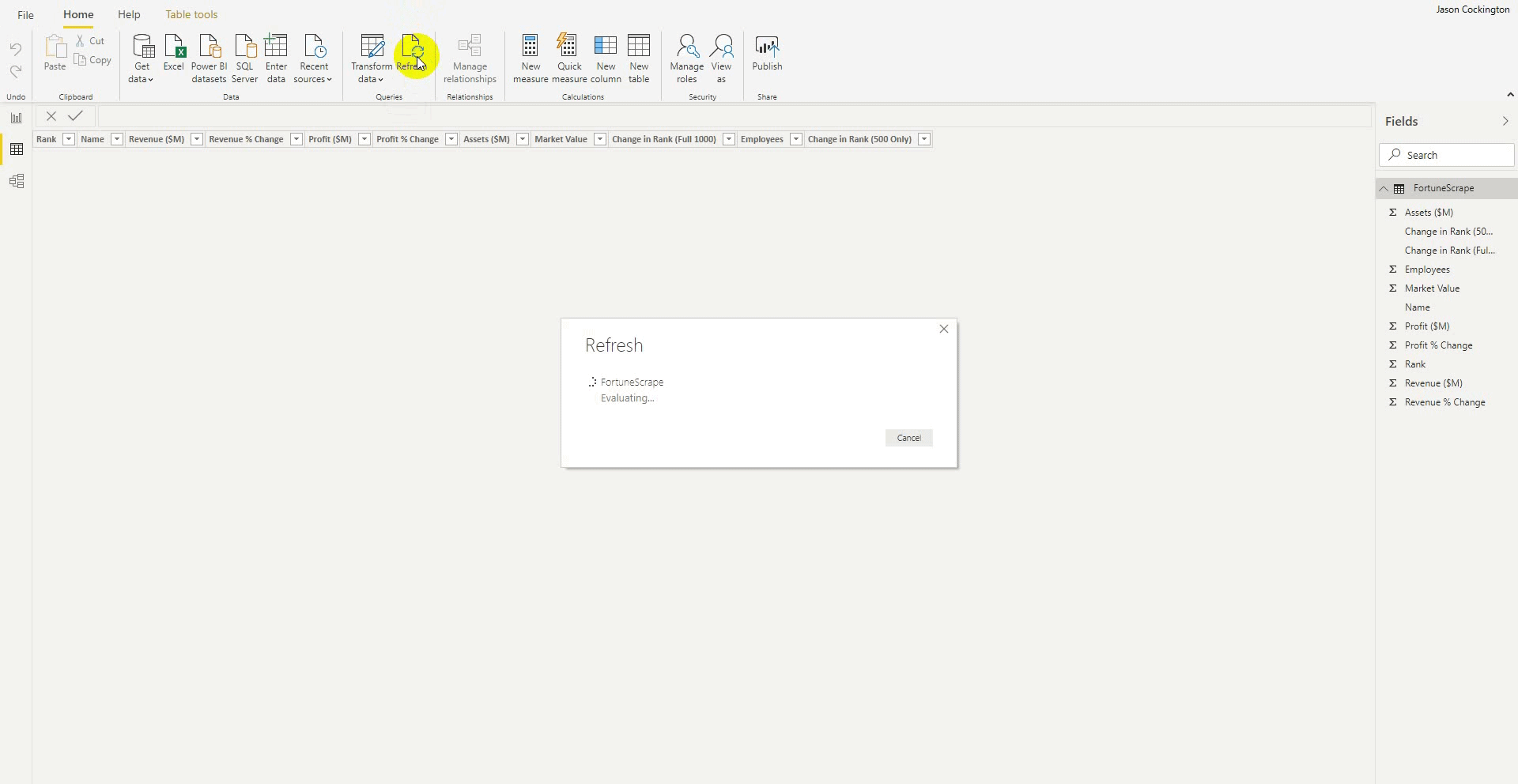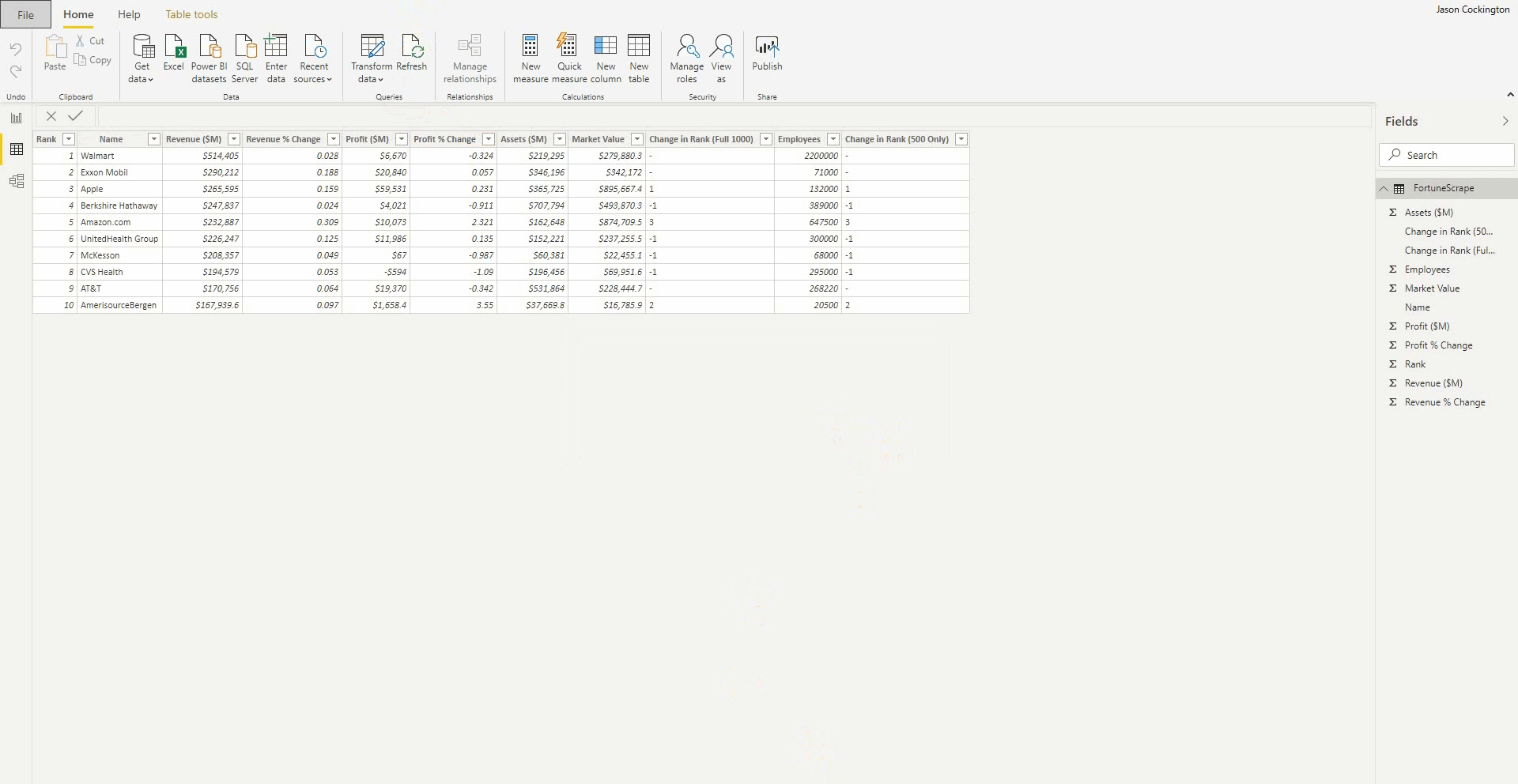
The data I want to extract is details of the Fortune 500 Companies, as listed by Fortune.com.
By examining the source code of the website, it is clear that the tabulated data presented to the audience is generated via a JavaScript instance, and does not exist as a static item on the page. In this case the web page generates the first 10 rows of the Fortune 500 list.

Before Turning on New Web Table Inference
If I try to extract the list without using the new preview feature, Power Query presents only a table captured from the footer of the page.


Note how Power Query was unable to identify the tabular structure of the core content of the page and instead offers a single object (Table 1) revealing the data from the Sections table of the footer contents. This standard approach to scraping is insufficient to get data from such a complex website and hence we need to use the new preview feature.
The Power of New Web Table Inference
With the new feature enabled, there are 2 table objects Power Query has detected. While Table 1 looks very similar to the contents of the dynamic table I am attempting to scrape, it is missing some of the columns, so I need to implement the “Add table using examples” button to train Power Query exactly what I am targeting.
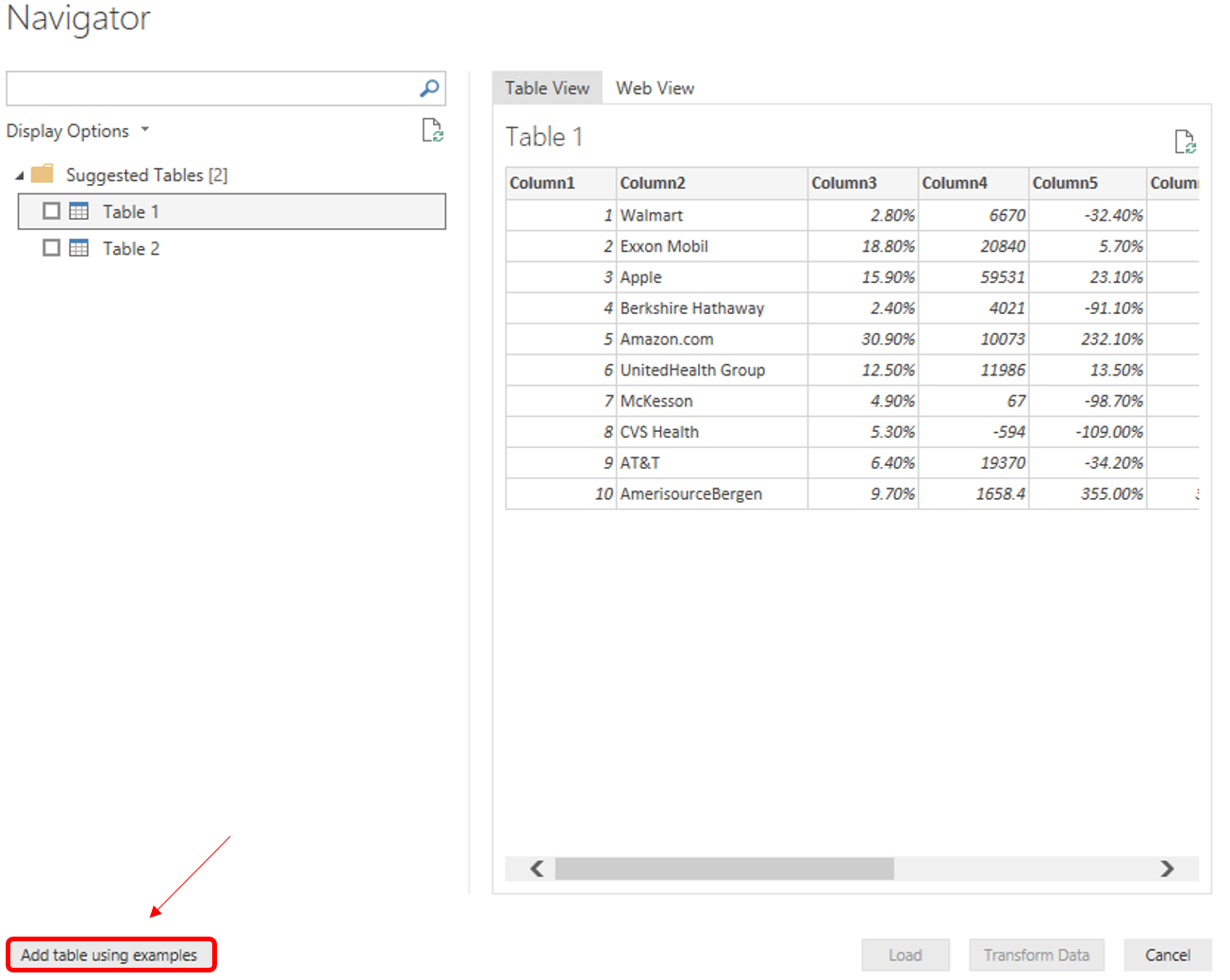
NOTE: If you are attempting this at home, and only see one table (Sections data) presented even after the New Web Table Inference feature is enabled, just close your Get Data wizard, and attempt to connect to the web data source again. Also, try adjusting the url to connect via http:// rather than https://. We’re pushing the capabilities of this new feature to the limits by asking it to scrape such a complicated website, and as the feature is still in development it doesn’t work perfectly every time.
Training the query
By clicking “Add table using examples”, Power Query allows you to build your own table by showing it what you expect the table to reveal. In this instance I am targeting the complete table, but it is best practice to just scrape the data you need.
After clicking the button you are presented with a split screen. At the top is an interactive version of the web page of your target website, and on the bottom will be a blank spreadsheet. As you start to fill in the spreadsheet data, Intellisense helps you select the valid fields, presenting a list of possible values. As you work through the spreadsheet, Power Query is learning which values in the website relate to the table, and by the time you have completed a second row value, Power Query will be able to recognise the pattern of the web data and auto populate the remaining rows. Then just click “OK” and load the data into Power BI.
NOTE: While the New Web Table Inference feature has an amazing ability to scrape data from these complicated websites, one limitation that currently exists with the technology is that it is only capable of scraping from what is shown on the default web page instance. So, in this example, even if you were to click and expand the data set to 100 rows, the Power Query engine is still only going to detect the first 10.

Refresh Your Query in Power BI
Finally, in the case that Power BI loaded empty tables after completing the Get Data wizard. Simply refresh your query to scrape the page again.
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.
Great article, I’m currently striving to get data from the results generated from the website below, unfortunately so far could not succeed, if you guys have any guess on how to do that I’d appreciate it.
https://venda-imoveis.caixa.gov.br/sistema/busca-imovel.asp?sltTipoBusca=imoveis
Interesting article! Thanks Jason.
One Question, Is there any way the power Query could also extract the subsequent pages?
Because with a chrome extension, Table capture; one can easily capture page by page. The issue is when there is a lot of data. what do you suggest?
If the table size is controlled by the URL, then one can simply alter the URL parameters to display more data on the page, and thus use the modified URL in the Web Connector.
Unfortunately though, if the table size is controlled by the page script (as it is in the above example), where the URL doesn’t change when the table is updated, then at this time I do not have a solution for capturing the additional content from the table.
Perhaps this could be achieved using Python.
What do you do if there is no preview to work with please e.g.
https://ec.europa.eu/esco/portal/occupation?uri=http%3A%2F%2Fdata.europa.eu%2Fesco%2Foccupation%2F31808988-fc0a-4bc3-9e47-27216d6759f5&conceptLanguage=en&full=true#&uri=http://data.europa.eu/esco/occupation/31808988-fc0a-4bc3-9e47-27216d6759f5
Hi Peter,
I had a quick look at your website, but there didn’t appear to be any tabulated information.
Power Query is designed to scrape tabulated data.
If you can forward a link directly to the data you are attempting to scrape, I may be able to assist further.
Hi, I have been trying to use this feature on this website:
https://asamblea.gob.pa/index.php/seguimiento-legislativo
It has a listing of all the law bills being discussed by congress in Panama. However when I try to scrape this address in Power BI with the new feature on the Navigator window, under Display Options, it shows “We didn’t find any tables on this web page”.
Any ideas as to how to connect PBI to this address?
Sorry, I have no suggestions. Power Query is constantly being updated and improved. For what ever reason PQ cannot access the data on this site.
Hi Alex,
Not sure if this is still of interest to you, but I can confirm that it is now possible in the June 2021 version of Power BI.
In order for you to fully scrape the website, you will need to tweak the process a little so that you can load the Document pdf urls.
Steps:
1. Connect to website and load basic table (no data in the Documents column)
2. Adjust source step so that it waits to fully load the html before proceeding (using the Waitfor command):
= Web.BrowserContents("https://asamblea.gob.pa/index.php/seguimiento-legislativo", [WaitFor = [Timeout = #duration(0,0,0,10)]] )3. Click on the gear icon on the Extracted Table from Html step
4. Check the pdf url on at least one of the documents on the source website
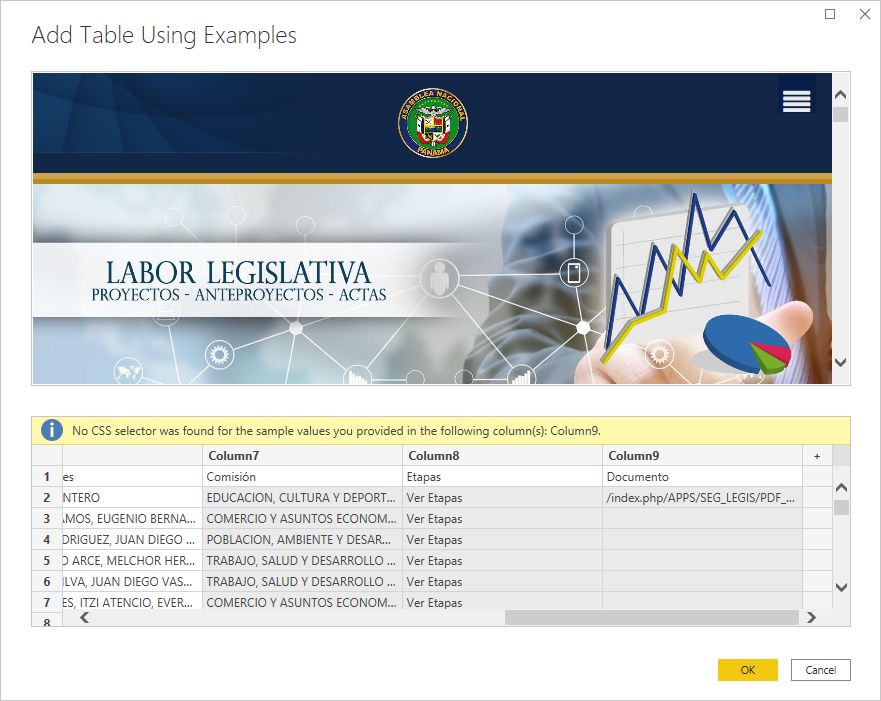
5. Populate column 9 (Documents) with the sample url details (in my case 2021_A was sufficient to bring up the list of urls).
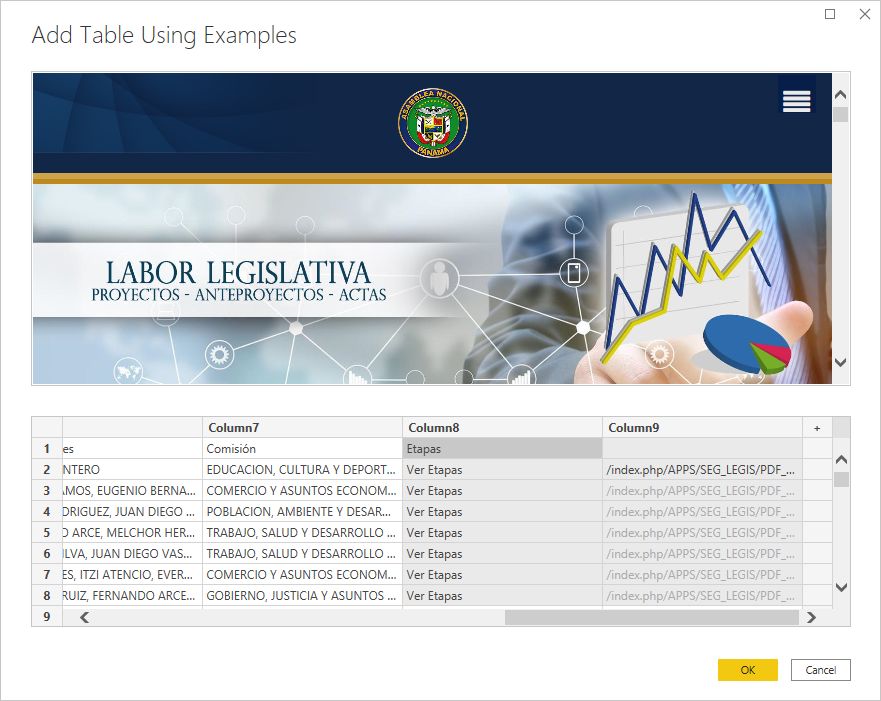
6. You will now see a CSS Selector error on the Table from Examples wizard:
7. Delete the “Documents” column header title from column 9
8. Click OK
9. Insert a Renamed Columns step before your Changed Type step and label column 9, Documents.
10. Close and Apply
11. Go to the data view in Power BI, select the Documents column, and change the Data Category to Web URL
I hope this helps anyone else who might have encountered the “No CSS selector was found for sample values…” error.
For a full breakdown on this technique, check out Miguel’s post, or if you prefer Vlogs, try Ruth’s demo
Hi Jason,
Thank you for the article.
I’m aware that you’re discussing Power Bi and this is an Excel Power Query question, but perhaps you’ve run across a similar situation. I have been scraping data from a website but the table that the web scraper has been configured to read appears to change/shift several times a day. I select table #6 and it reads the file, but the next time I go into Excel I get an error, and the values for that particular table are instead in table number #2.
I wonder if it may be an issue with cookies? I have been scraping similar pages from other websites but have not been running across this issue.
mmmm, tough. My guess is that there is some application at the back end that is rendering the web pages, and the technical name of the tables is not important to the end user experience. The only idea I can think of is to use the “try” function and a parameter. I haven’t thought this through fully, but I am thinking you could create a parameter for the table number and then create a function. You pass a list of possible values to the parameter inside a “try” construct to see if it works, or if it throws an error. Repeat until it works. I seem to remember learning about try from Chris Webb, so you could try searching for that. I think it is in his book, but also here https://blog.crossjoin.co.uk/2016/08/09/handling-404-not-found-errors-with-web-contents-in-power-query-and-power-bi/
Same for me, trying to connect to the data from Algeria, I get the same issue “table2 not showing”. Tried with https:// and with http:// and same result.
Anyway, thank you for sharing
Hi Mehdi,
I am sorry you’re having trouble getting this to work.
I assume you have attempted to connect multiple times, to no avail?
I find it only detects the Java Table about 10% of the time.
As I mentioned in the post, we’re really pushing the intention of the webscrape capabilities with this task, so it doesn’t always work.
Unfortunately, table 2 is not showing for me. I enabled the New Web Table Inference, restarted Power BI Desktop and attempted the connection around 10 times, to no avail.
Anyway, thanks for the post. That’s going to be a nice feature.
Hi Danilo,
Try connecting to the site via http:// instead of https://
this usually works.
Hi Jason,
That did the trick. Thanks!
1) I won’t get a second table 🙂
2) How could you get Power BI to accept/reject cookies?
I found no way to skip the window, which might pop up only in Europe (!?).
After it disappears due to timeout, intelligence won’t even recognize Walmart.
Hi Frank,
Try connecting to the site via http:// instead of https://
this usually works.
Hi Jason,
http:// doesn’t help.
I’m pretty sure Power BI cannot handle this pop-up screen, which here in Europe is more or less standard now:
“We and third parties use cookies or similar technologies (“Cookies”) as described below to collect and process personal data, such as Cookie or browser information. Please choose whether this site may use Cookies as described below. By clicking “Submit Preferences”, you accept the placement and use of these Cookies for these purposes. You can change your mind and revisit your preferences at any time by accessing the “Cookie Preferences” button in the footer of this site. You can learn more about how this site uses Cookies and related technologies by reading our privacy policy linked below.”
Hi Frank
Thanks for the information.
I think you’re right. The pop up is likely breaking your scrape.
Unfortunately, I don’t know of any way around this.
Very interesting finding.
Thanks.