Finding the Date of the Next Record in Power Query
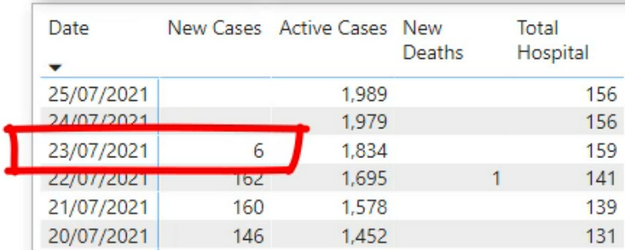
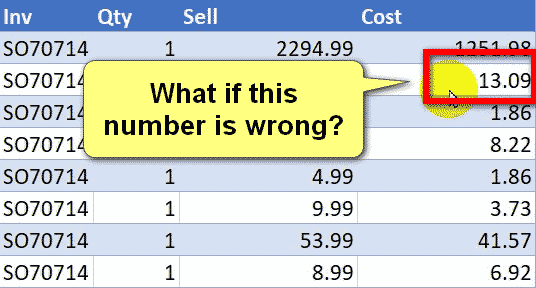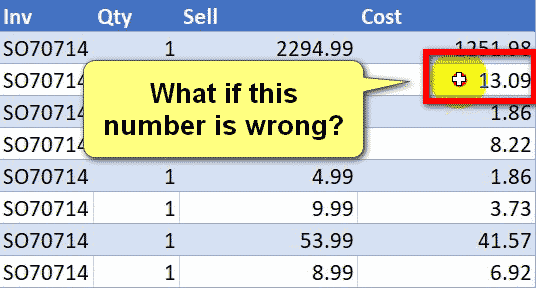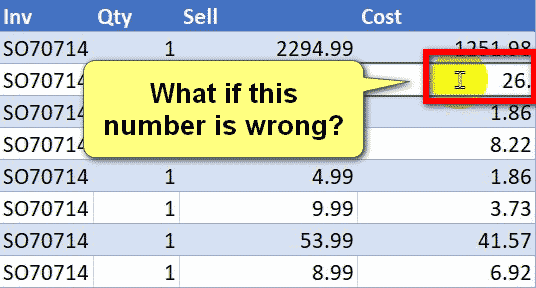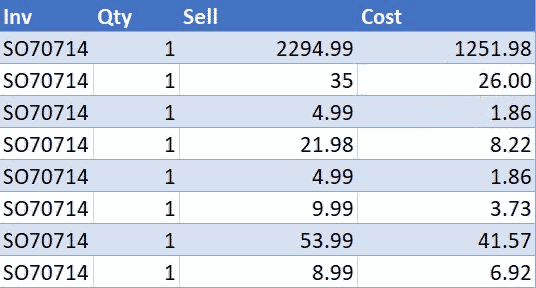
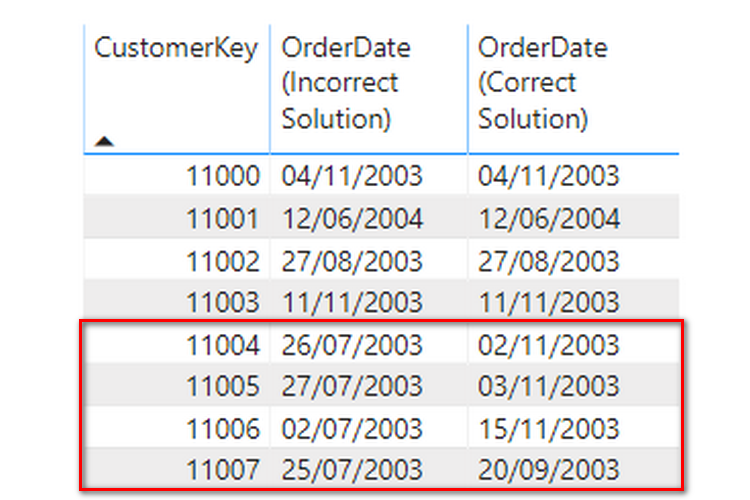
Today I’m going to share my solution to a question I found on the MrExcel forum. It’s an interesting problem. https://www.mrexcel.com/board/threads/power-query-to-determine-consecutive-and-non-consecutive-dates.1261496/ Let me briefly explain the problem. The Problem We have the following table, which contains the source data. Each row contains a unique ID (maybe a piece of equipment) […]